



Ayudar a los usuarios bien intencionados
El SISAM se concibió al objeto de detectar errores en los códigos de clasificación arancelaria, y no para ayudar a los importadores y exportadores bien intencionados a clasificar las mercancías. Con este fin, se creó un nuevo sistema denominado CLASSIF[1]. Este sistema analiza la clasificación de las mercancías utilizando los códigos de la NCM, que se basan en los códigos del Sistema Armonizado de Designación y Codificación de las Mercancías (SA), pero con dos dígitos adicionales. Los importadores y exportadores pueden introducir la descripción de un producto en el sistema y este les muestra información sobre los códigos de la NCM que contienen los términos utilizados en la descripción, las notas legales relacionadas con dichos códigos, así como las Notas explicativas pertinentes del Sistema Armonizado de la OMA, las resoluciones anticipadas relativas a dichos códigos y, por último, propuestas de clasificación que proceden directamente del SISAM.
De hecho, hemos adaptado el SISAM para que estime las probabilidades únicamente en función de la descripción de las mercancías, descartando los demás atributos utilizados habitualmente. Este método debilita un tanto el modelo, pero ofrece a cambio la ventaja de que no muestra a los usuarios el modo de engañar al sistema. Si un importador mal intencionado continúa cambiando la descripción hasta que CLASSIF le propone el código deseado, ello no es óbice para que el SISAM no detecte el error más adelante. El resultado en lo relativo a los importadores sigue siendo satisfactorio.
Un artículo publicado recientemente en el World Customs Journal[2] detalla una lista de mercancías que se pueden utilizar para poner a prueba la capacidad de los sistemas de ayuda en materia de aranceles aduaneros en lo relativo a encontrar los códigos correctos del SA, ya que cada producto presenta dificultades concretas para estos sistemas. Tradujimos la lista al portugués y la introdujimos en el sistema CLASSIF. Los resultados se muestran en el cuadro 1. Cabe mencionar que el CLASSIF fue programado para proponer un código de 8 dígitos cuando se considera que la calidad del resultado es alta, y un código de solo 4 dígitos cuando la calidad es baja.
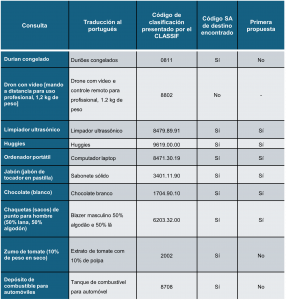
Cada vez que el CLASSIF proponía un código de 8 dígitos, el resultado era correcto, y el código correcto era el código que el sistema proponía como el que tenía mayor probabilidad de exactitud. Esto ocurrió en seis de cada diez intentos. En tres ocasiones, el CLASSIF propuso un código correcto de 4 dígitos, si bien no como primer resultado más probable, pero siempre dentro de las diez primeras alternativas. Tan solo en una ocasión, el CLASSIF falló por completo. El problema fue debido a la presencia de datos “basura” en la base de conocimientos del SISAM que se resolverá en breve.
Ayuda para la auditoria de control a posteriori (ACP)
El SISAM se creó inicialmente para ayudar a seleccionar las declaraciones de importación a efectos de su control en zonas primarias. No obstante, sus informes de riesgo se pueden agrupar de diversas formas, por ejemplo, por empresas o por clasificación arancelaria. Estos grupos de datos pueden ser de utilidad para los equipos encargados de las ACP y contribuir además a desplazar los controles aduaneros hacia la fase de la auditoría a posteriori, en consonancia con los acuerdos de facilitación del comercio. Actualmente, en lugar de crear mecanismos de agrupación en el SISAM, preferimos alimentar nuestro lago de datos con informes individuales del SISAM que pueden agruparse utilizando un software como Power BI, CONTÁGIl[5], ANALYTICS[6], Jupyter Notebook, HUE y SPARK.
Utilizar la experiencia adquirida para elaborar nuevos sistemas
Se han introducido nuevos sistemas para reforzar la capacidad del país en la gestión y seguimiento del comercio internacional y la circulación de viajeros.
Un entorno de ventanilla única
Brasil se encuentra actualmente en proceso de elaboración de un nuevo sistema de ventanilla única para el comercio exterior, conocido como Portal Único do Comércio Exterior (PUCOMEX).[7] Este sistema optimiza y centraliza la tramitación de los documentos relacionados con el comercio, ofreciendo importantes ventajas a las empresas, especialmente en cuanto a la reducción del tiempo y los costes asociados con las operaciones transfronterizas. En cuanto a la Administración de aduanas, PUCOMEX ofrece considerables ventajas en relación con el control y la gestión de los flujos comerciales internacionales. Esta plataforma centralizada permite un seguimiento más eficaz y una mejor coordinación entre los distintos organismos gubernamentales que intervienen en el control aduanero y fronterizo.
La creación de PUCOMEX se asienta sobre las experiencias altamente satisfactorias de los programas informáticos aduaneros desarrollados internamente, como, por ejemplo, ANIITA y PATROA. Si bien PUCOMEX es obra de una empresa externa, Serpro (Servicio federal de procesamiento de datos), aprovecha ampliamente los conocimientos y la experiencia adquiridos en estos proyectos internos. El método adoptado ha demostrado ser sumamente beneficioso, ya que ofrece flexibilidad para experimentar antes de pasar a un sistema más robusto y al contar con una empresa especializada que se encarga del desarrollo y el mantenimiento de la nueva plataforma.
Integrar los sistemas de la Aduana y de las compañías aéreas para el control de viajeros
Nuestro sistema de control de viajeros está actualmente integrado en los sistemas de las compañías aéreas y evalúa los riesgos teniendo en cuenta la situación económica de los viajeros, el itinerario elegido, los viajes realizados previamente y los compañeros de viaje no declarados, pero repetidos.[8],[9] En los aeropuertos se utilizan igualmente dispositivos de reconocimiento facial directamente conectados con los sistemas aduaneros.
Hacer el seguimiento de los vehículos
Un sistema denominado SIVANA se encarga de supervisar los vehículos cerca de las fronteras terrestres de Brasil utilizando las imágenes tomadas por las cámaras de vigilancia en carretera. Dicho sistema permite a los funcionarios aduaneros analizar las rutas utilizadas por los vehículos seleccionados y recibir información en tiempo real sobre su ubicación, lo que propicia una respuesta rápida a las posibles amenazas, especialmente las relacionadas con el tráfico de estupefacientes y el comercio de productos falsificados.
Con miras a mejorar las capacidades de SIVANA, especialmente en la identificación de pautas o anomalías que pudieran indicar la existencia de actividades ilegales en las fronteras terrestres de Brasil, hemos establecido una sociedad con Itaipu Parquetec, un ecosistema innovador compuesto por diversas entidades, a saber, instituciones educativas, empresas y organismos gubernamentales. Con ello se persigue desarrollar una aplicación denominada SMART WALL, que utiliza el análisis bayesiano y el aprendizaje profundo.
Asegurar la coherencia de los datos en todos los documentos comerciales
Otro ejemplo de tecnología innovadora es el sistema BATDOC [10], creado para comparar declaraciones de importación (que son documentos electrónicos destinados a ser entendidos por un ordenador) acompañadas de documentos justificativos que se presentan todavía en formato digital o imágenes escaneadas de formularios originales, como facturas y conocimientos de embarque. Este sistema permite garantizar la coherencia de los datos en todos los documentos. Mediante la tecnología de reconocimiento óptico de caracteres (OCR), BATDOC compara automáticamente información fundamental, como el nombre y la dirección de las partes implicadas, así como la cantidad y el valor de las mercancías. Al cruzar las referencias de estos documentos, BATDOC permite controlar los errores y discrepancias, reforzando así la exactitud y fiabilidad de la información.
Aprovechar la pericia externa para automatizar el análisis de imágenes por rayos X
Una importante limitación del SISAM reside en la imposibilidad de incorporar a su análisis imágenes de rayos X. Para paliar esta deficiencia, se puso en marcha el proyecto AJNA. AJNA[11] es un sistema impulsado por una red neuronal de aprendizaje profundo, que recopila, muestra y analiza imágenes de rayos X de forma automatizada.
En un principio, el AJNA se aplicó exclusivamente en Port of Santos, uno de los mayores puertos de América latina. El sistema gestiona procesos como la recopilación de imágenes desde los escáneres de los almacenes aduaneros, el almacenamiento centralizado y normalizado de dichas imágenes y su recorte para aislar los contenedores de los camiones que los transportan. Además, el AJNA puede detectar mercancías en contenedores que están supuestamente vacíos.
Al igual que el SISAM, el AJNA fue creado con la idea de que fuera un equipo interno quien se ocupara de su desarrollo y mantenimiento. No obstante, si bien el SISAM era el único proyecto de inteligencia artificial en fase de desarrollo en aquel momento, el lanzamiento del AJNA se produjo conjuntamente con otros casi 40 proyectos relacionados con la inteligencia artificial. Pronto se hizo necesario recurrir a la pericia externa para continuar desarrollando la aplicación. Actualmente se están llevando a cabo dos proyectos con empresas privadas.
Utilizar las imágenes de rayos X para detectar los errores de clasificación
El primero de estos proyectos, denominado X-Class, pretende utilizar las imágenes de rayos X para detectar errores de clasificación. Optamos por trabajar con una empresa emergente porque estábamos convencidos de que únicamente un modelo de aprendizaje profundo meticulosamente elaborado podía gestionar todas las peculiaridades del proyecto y porque disponemos de millones de imágenes y de declaraciones de importación correspondientes para entrenar el modelo.
Se trata de una tarea compleja ya solo por la existencia de más de 10.000 códigos. Si bien algunos de estos códigos corresponden a mercancías que producen patrones claros y fácilmente reconocibles en las imágenes de rayos X, otros corresponden a mercancías que producen imágenes bastante similares. Para complicar aún más esta tarea, un mismo contenedor puede transportar diferentes tipos de mercancías, lo que produce patrones superpuestos difíciles de distinguir. El hecho de que solo se pueda utilizar un solo haz de rayos X complica aún más el problema, dificultando todavía más la tarea de separar e identificar con exactitud los diversos tipos de mercancías presentes en un mismo contenedor.
Afortunadamente, el SISAM enviará los resultados del análisis de clasificación a X-Class, reduciendo así considerablemente el número de códigos probables. Es posible que X-Class sea todavía incapaz de reconocer un producto en algunos casos, pero, al menos, suprimirá las propuestas del SISAM que resulten incompatibles con las imágenes observadas.
Utilizar Google Gemini para analizar imágenes de pequeños paquetes y el equipaje de los viajeros
El segundo proyecto está relacionado con los pequeños paquetes y el equipaje de los viajeros. Para ayudar a analizar las imágenes escaneadas, decidimos utilizar el modelo Google Gemini. Se trata de un modelo entrenado previamente y multimodal, es decir, capaz de tratar y analizar mucho más que solo texto. Tras mostrarle una imagen, Gemini puede describirla y responder a preguntas sobre el contenido, resumirlo y hacer extrapolaciones en función del mismo.
De este modo, resulta innecesario utilizar datos para entrenar el modelo. En su lugar, los funcionarios aduaneros deben formular preguntas al sistema en portugués. Existen dos tipos de preguntas. Los funcionarios pueden pedir a la máquina que detecte un artículo definido previamente, como drogas, armas o productos derivados de la fauna salvaje. Preguntarán, por ejemplo : ¿“hay drogas en este equipaje?” o ¿“hay algo que se parezca al esqueleto de un pájaro en este paquete?”. Las preguntas del segundo tipo son más sofisticadas y pueden utilizarse para detectar la evasión de impuestos, por ejemplo : ¿“hay algo en este paquete que no se corresponda con la descripción facilitada, que era …?”
Hasta ahora, solo se han probado las preguntas de primer tipo con resultados prometedores. Las imágenes de rayos X de pequeños paquetes son mucho más precisas que las imágenes de contenedores y suelen hablar por si solas, reduciendo así la necesidad de integración con otras herramientas de análisis.
Conclusión
El uso de la inteligencia artificial, que hasta hace muy poco constituía una novedad, se ha extendido por toda la Administración de aduanas de Brasil. La resistencia inicial, producto de la incertidumbre y el escepticismo, se ha logrado superar y ha dado paso a una demanda masiva de soluciones en el ámbito informático. Nuestro modelo de desarrollo inicial, que giraba únicamente alrededor de un equipo interno, tuvo que extenderse para dar cabida a socios como universidades, parques de innovación grandes tecnológicas, empresas emergentes y al Servicio federal de tratamiento de datos de Brasil. Todavía estamos aprendiendo a gestionar esta nueva realidad.
La inteligencia artificial no es algo que flota en espacio, debe estar conectada a un amplio ecosistema tecnológico que abarca distintas herramientas de recopilación de datos, bases de datos múltiples, herramientas de visualización de datos, sistemas de alerta en tiempo real, sistemas heredados, nuevos sistemas internos, sistemas gubernamentales distintos de la Secretaría de Ingresos Federales de Brasil y sistemas de empresas privadas. Estas integraciones suponen frecuentemente una parte significativa de los trabajos de desarrollo.
Nuestros sistemas de inteligencia artificial aprenden de las personas, sin intentar sustituirlas, y todas las decisiones adoptadas por estos sistemas son revisadas. Siempre que es posible, nuestros sistemas ofrecen explicaciones que nos ayudan a revisar dichas decisiones.
La inteligencia artificial se ha convertido en una herramienta indispensable para gestionar las complejidades del comercio moderno. Aunque ya se han conseguido resultados significativos, como un tratamiento más exacto y eficaz de los datos de las transacciones, aún queda mucho por hacer en el futuro.
Para más información
jorge.jambeiro@rfb.gov.br
gustavo.coutinho@rfb.gov.br
kelly.morgero@rfb.gov.br
[1] Jambeiro Filho, Jorge. Artificial Intelligence in the Customs Selection System through Machine Learning (SISAM). Prêmio de Criatividade e Inovação da RFB, 2015 (Premio de la creatividad y de la innovación de RFB 2015). https://www.jambeiro.com.br/jorgefilho/sisam_mono_eng.pdf
[2] Coutinho, Gustavo. Aniita – uma abordagem pragmática para o gerenciamento de risco aduaneiro baseada em software. Prêmio de Criatividade e Inovação da RFB, 2012 (Premio de la creatividad y de la innovación de RFB 2012). http://repositorio.enap.gov.br/handle/1/4607
[3] Domingues, Luiz Henrique; Navarro, Claudia Elena Figueira Cardoso; Steckel, Carlos Humberto; Lima, Lucas Araújo de; Casado, Marco Antônio Rodrigues. Prêmio de Criatividade e Inovação da RFB, 2023(Premio de la creatividad y de la innovación de RFB 2023). https://ea.ufba.br/wp-content/uploads/2023/11/E-book-A_22-premio_16_abr24.pdf
[4] Grainger, Andrew. Customs Tariff Classification and the Use of Assistive Technologies. World Customs Journal, 2024.
[5] Figueredo, Gustavo Henrique Britto. Um novo paradigma na auditoria em meio digital. Prêmio de Criatividade e Inovação da RFB, 2010 (Premio de la creatividad y de la innovación de RFB 2010). https://repositorio.enap.gov.br/handle/1/4580
[6] Receita Federal do Brasil. Receita Federal apresenta ferramentas de gerenciamento de riscos em evento informal da OCDE na Suécia. 2024.
[7] Corbari, Jackson Aluir; Zambrano, Alexandre da Rocha; Morgero, Kelly Cristina Silva. Portal Único Siscomex: A transformação digital no comércio exterior brasileiro. 2024.
https://alfandegas.cplp.org/Newsletter/Documents/Newsletter%208%20janeiro%202024_VF.pdf
[8] Moraes, Felipe Mendes. Sistema e-DBV – Módulo viajante único, 2017. https://repositorio.enap.gov.br/handle/1/4635
[9] Thompson, Ronald Cesar. Projeto IRIS – Reconhecimento facial de viajantes. 2016. https://repositorio.enap.gov.br/handle/1/4627
[10] Barbosa, Diego de Borba. Batimento Automatizado de Documentos na Importação – BatDoc. Prêmio de Criatividade e Inovação da RFB, 2016 (Premio de la creatividad y de la innovación de RFB 2016). http://repositorio.enap.gov.br/handle/1/4630
[11] Brasílico, Ivan. AJNA – Plataforma de Visão Computacional e Aprendizado de Máquina. Prêmio de Criatividade e Inovação da RFB, 2017 (Premio de la creatividad y de la innovación de RFB 2017). https://repositorio.enap.gov.br/jspui/handle/1/4634