La Douane indienne a fortement avancé dans ses efforts pour se doter de capacités de ciblage systémiques et en temps réel grâce à la mise au point d’un système de gestion des risques intégré sous-tendu par l’intelligence artificielle et l’apprentissage automatique. L’un des piliers de ce système est la codification des coordonnées des fournisseurs et des descriptions des marchandises. Le présent article se penche sur le fonctionnement de cette codification et explique comment elle est utilisée pour analyser les réseaux de la chaîne logistique, autogénérer des observations concernant les risques et détecter les anomalies en matière d’évaluation.
Codification des entreprises : l’épine dorsale du ciblage automatisé des risques
Disposer de données codifiées et lisibles à la machine, tel est le fondement de l’évaluation et du ciblage automatisés des risques en douane. La codification de toutes les entreprises dans la chaîne logistique permet notamment aux administrations des douanes de s’attaquer plus efficacement aux risques liés aux recettes et à d’autres domaines, et de visualiser les réseaux solides qui existent entre entreprises aux fins d’une analyse des risques exhaustive. Si des codes uniques ont déjà été assignés aux entités de la chaîne logistique telles que les importateurs et les agents en douane, les informations concernant les fournisseurs étrangers sont traditionnellement saisies dans les déclarations d’importation dans un format de texte libre. Ces données non structurées posent un énorme défi pour l’analyse automatisée des risques, en particulier lorsque le même fournisseur livre des marchandises à plusieurs importateurs dans un même pays.
Attribuer des codes uniques aux fournisseurs établis à l’étranger
Pour résoudre ce problème, la Douane indienne a décidé d’attribuer un identifiant unique aux fournisseurs en se basant sur leur nom et leur adresse professionnelle tels que renseignés dans la déclaration à l’importation. Un modèle d’apprentissage automatique non supervisé a été mis au point pour effectuer cette tâche. Dans un premier temps, le nom et l’adresse des fournisseurs ont été extraits des déclarations d’importation, puis nettoyés et normalisés en utilisant des techniques de traitement du langage naturel et d’analyse de texte. Des algorithmes d’appariement de chaînes de caractères ont ensuite été appliqués pour évaluer la similitude entre les entrées fournisseurs, après quoi des algorithmes d’agrégation ont regroupé les entreprises montrant une grande force d’appariement, sur la base de seuils prédéfinis. Enfin, des algorithmes de distance, comme la distance de Jaro-Winkler et la distance de Levenshtein, ont été utilisés pour déterminer la proximité des données simples par rapport aux agrégats.
L’exercice a abouti à la création de codes fournisseur, c’est-à-dire d’identifiants uniques assignés à tous les fournisseurs sur la base d’attributs essentiels comme leur nom, leur adresse et leur pays. À titre d’exemple, les variations dans les coordonnées « fournisseur » reproduites ci-dessous, qui se réfèrent toutes au même opérateur, sont consolidées sous un même code : A88000001.
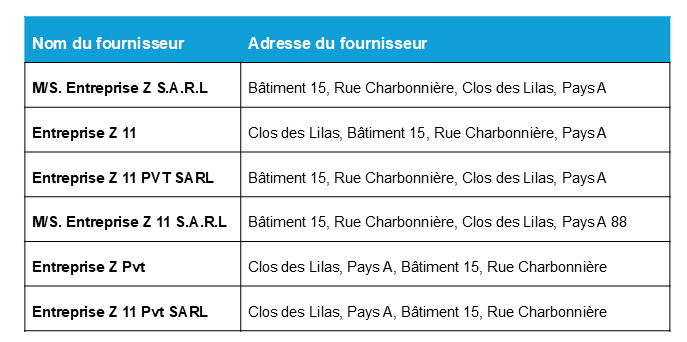
La codification permet au système de gestion des risques douanier de traiter toutes les variantes comme un seul fournisseur, ouvrant ainsi la voie à un ciblage et à une analyse de réseaux de la chaîne logistique plus précis.
Codifier la description des produits pour pallier les risques liés aux recettes
Faisant fond sur la codification des fournisseurs, la codification des descriptions de produits joue un rôle décisif pour la détection des risques en lien avec les recettes, comme le classement incorrect de marchandises et la sous-évaluation. Les descriptions de produits, tels qu’elles apparaissent sur les factures et les déclarations d’importation, manquent souvent de structure et de cohérence, même lorsqu’un même fournisseur livre des produits identiques.
Face à cette difficulté, la Douane indienne a développé un système de codification des descriptions, où un modèle d’apprentissage automatique non supervisé attribue un indicatif de description normalisé aux marchandises fournies par chaque fournisseur codifié. Le processus de codification des descriptions implique plusieurs étapes orientées apprentissage automatique, qui convertissent les descriptions de produit non structurées en données normalisées. Les descriptions en format de texte libre sont extraites des déclarations à l’importation. Grâce aux techniques de traitement du langage naturel, le texte est nettoyé et normalisé en supprimant les détails non pertinents comme la ponctuation ou encore les mots vides. Les descriptions similaires sont regroupées en utilisant des algorithmes d’agrégation et des paramètres de mesure de similitude lexicale. Les articles présentant un haut degré de similarité textuelle et sémantique se voient attribuer le même indicatif de description.
Cet indicatif relie les variantes descriptives pour une même marchandise provenant d’un même fournisseur à une catégorie unique et analysable. Pour revenir à l’exemple ci-dessus, le fournisseur A88000001 décrit les mêmes parties d’automobile de diverses manières, comme indiqué dans le tableau ci-après.

Toutes les variantes ci-dessus, même si elles sont libellées différemment, sont reconnues comme étant le même produit livré par le même fournisseur et portant l’indicatif de description qui lui a été attribué, à savoir « 1 ». Cet indicatif permet à la Douane de comparer les valeurs déclarées par différents importateurs pour un même produit provenant d’un même fournisseur, de détecter les envois sous-évalués et de garantir le classement adéquat des marchandises.
Analyse de réseaux de la chaîne logistique
La codification des entreprises permet aux autorités douanières d’analyser les relations entre les acteurs principaux de la chaîne logistique, y compris les fournisseurs, les importateurs, les agents en douane et les ports d’importation, pour une évaluation des risques et un ciblage plus précis.
Le modèle d’analyse de réseaux tire les données avant tout des déclarations à l’importation et à l’exportation, en utilisant des paramètres spécifiques d’entrée comme le numéro d’identification de l’importateur/de l’exportateur, le code des agents en douane et l’identifiant codifié des fournisseurs. Pour chaque numéro d’identification d’une entité, les données pertinentes sont extraites des systèmes sources, puis nettoyées et normalisées en utilisant des techniques d’analyse de texte et de traitement du langage naturel. Les données ainsi préparées servent à construire des réseaux précis, où les nœuds individuels représentant les fournisseurs, les importateurs/exportateurs et les agents en douane sont identifiés et étiquetés de manière distincte. En utilisant les techniques avancées de modélisation de réseaux, les nœuds sont reliés pour former des réseaux exhaustifs de relations dans la chaîne logistique. Un outil de visualisation affiche ces réseaux interconnectés, donnant ainsi la possibilité aux douaniers d’étudier les connexions entre entreprises ou entités, de détecter les anomalies et, partant, de recenser les entreprises et les transactions à haut risque.
Modèles avancés de gestion des risques
La mise en œuvre réussie de la codification des entreprises et des descriptions a ouvert la voie à la création d’un ensemble de modèles de gestion des risques conçus pour renforcer la précision du ciblage, la prise de décisions et l’efficacité opérationnelle de la Douane indienne.
Le premier modèle de « Ciblage prédictif basé sur les fournisseurs et les descriptions » applique un ciblage ou une interdiction spécifique aux fournisseurs signalés comme représentant un risque élevé, permettant ainsi de passer au crible chaque entreprise de manière granulaire et pointue.
Le « Modèle d’évaluation basée sur l’apprentissage automatique », qui tire parti de la codification des fournisseurs et des indicatifs de description pour évaluer la valeur déclarée des marchandises en temps réel, représente une importante avancée pour l’autorité douanière indienne. En comparant les valeurs déclarées présentement pour chaque article dans un envoi avec les données historiques portant sur les mêmes marchandises du même fournisseur, le modèle génère des instructions automatiques ainsi que des points de référence fondés sur les tendances dégagées à partir des déclarations passées, que les douaniers peuvent ensuite utiliser pour évaluer les marchandises avec plus d’exactitude et pour déceler les cas de fraude.
Autre avancée notable, le « Module d’observations » utilise l’intelligence artificielle et l’apprentissage automatique pour offrir une analyse exhaustive à 360 degrés des fournisseurs, des importateurs, des agents en douane et des marchandises. Ce module recourt à l’analyse de réseaux pour évaluer le comportement des entreprises impliquées dans des transactions commerciales et offre des observations basées sur les données historiques, aidant ainsi les douaniers à détecter les anomalies et à dégager les tendances dans les comportements commerciaux.
« L’Outil d’analyse après saisie » a été conçu pour générer des constatations spécifiques pour chaque type d’infraction, à travers l’analyse relationnelle, en utilisant la codification des fournisseurs et les indicatifs de description. L’outil se focalise sur l’analyse du comportement des fournisseurs, des importateurs et des agents en douane impliqués dans des transactions frauduleuses. Il aide à attribuer des notes de risque et à renforcer les capacités prédictives du système de gestion des risques. Les infractions enregistrées influencent directement les profils de risque des entreprises associées, rendant les évaluations de risque futures plus précises.
Le « Modèle de corrélation Fournisseur-Importateur » offre des informations détaillées sur les importateurs et les agents en douane associés à un fournisseur donné, ce qui aide les douaniers à évaluer la bonne foi du fournisseur et à prendre des décisions raisonnées sur le risque qu’il peut poser. Enfin, la « Base de données des infractions » sert de répertoire centralisé des infractions en lien avec les codes des entreprises et les indicatifs de description. Cette base de données sert de référence pour les alertes de risque en temps réel qui sont envoyées aux douaniers de première ligne, offrant ainsi des informations sur le comportement passé des fournisseurs, des importateurs et des agents en douane. Elle joue un rôle essentiel pour la détection active des envois à haut risque en recoupant les codes fournisseur, les codes importateur et les identifiants de produits avec les tendances enregistrées en matière d’infractions.
La précision de ces modèles de gestion des risques est régulièrement évaluée en utilisant des indicateurs clés de performance (KPI). Les principales mesures couvrent notamment la précision avec laquelle les modèles de gestion des risques détectent les envois à haut risque, le montant des recettes recouvrées grâce à la détection des cas de classement incorrect ou de sous-évaluation des marchandises, la précision du ciblage prédictif des entreprises sur la base de leur performance historique, les taux de résultats faux positifs et le taux de détections.
L’utilisation des modèles a abouti à d’importants résultats, notamment la saisie de 294 kg d’héroïne passés en contrebande depuis l’Afghanistan au port de Nhava Sheva, de 883 kg de méthamphétamine cachés dans un chargement maritime à l’importation, et de 7,9 millions de cigarettes d’une marque étrangère. Plusieurs envois illicites de déchets électroniques et d’autres articles frappés d’interdictions et de restrictions ont également été découverts, ainsi que des cas de fraude commerciale.
Transformer les données en renseignement exploitable
L’intégration de modèles d’intelligence artificielle et d’apprentissage automatique dans le système de gestion des risques de la Douane indienne livre des résultats mesurables et en temps réel. Ces modèles génèrent des alertes quotidiennes et contribuent à une meilleure prise de décisions pour les douaniers de première ligne, améliorant ainsi grandement la précision et l’efficacité des actions de lutte contre la fraude. La codification des entreprises et les indicatifs de description normalisés constituent un fondement essentiel pour d’autres modèles avancés d’intelligence artificielle et d’apprentissage automatique utilisés aux fins de la gestion des risques douaniers. En transformant les données non structurées de la déclaration en formats structurés et lisibles à la machine, la Douane indienne a amélioré sa capacité à détecter avec plus d’exactitude les risques liés tant aux recettes qu’à d’autres domaines, renforçant ainsi la sécurité des échanges commerciaux transfrontaliers. La gestion efficace des risques et le mouvement sécurisé des marchandises peuvent ainsi pleinement contribuer à la prospérité de toutes les parties prenantes impliquées dans le commerce international.
En savoir +
sruti.vijayakumar@gov.in
shivam.dhamanikar@gov.in


