



Aider les usagers bien intentionnés
Le SISAM a été conçu pour détecter les erreurs au niveau des codes de classement des marchandises et non pour aider les importateurs et les exportateurs bien intentionnés à classer leurs produits. À cette fin, un nouveau système a été créé : le CLASSIF[1]. Ce système analyse la classification des marchandises en se basant sur la Nomenclature commune du Mercosur (NCM), qui se fonde elle-même sur les codes du Système harmonisé de désignation et de codification des marchandises (SH), mais en y ajoutant deux chiffres supplémentaires. Les importateurs et exportateurs peuvent saisir la description d’un produit dans le système et ce dernier leur montre alors des renseignements tels que le code NCM et son libellé, les notes légales s’y rapportant ainsi que les Notes explicatives pertinentes du Système harmonisé de l’OMD, les décisions anticipées concernant ce code et, enfin, des propositions de classement émanant directement du SISAM.
Nous avons d’ailleurs adapté le SISAM afin qu’il estime les probabilités uniquement sur la base de la description des marchandises donnée par les utilisateurs, en contournant les autres attributs qu’il utilise normalement. Cette approche affaiblit quelque peu le modèle mais l’avantage est qu’elle ne montre pas aux utilisateurs comment tromper le SISAM. Même si un importateur mal intentionné venait à changer constamment la description d’un produit jusqu’à ce que le CLASSIF lui suggère le code qu’il souhaite utiliser, le SISAM ne manquera pas de détecter l’erreur plus tard dans le processus. Le résultat concernant les importateurs reste satisfaisant.
Un article publié récemment dans le World Customs Journal[2] présente une liste de marchandises à utiliser afin de tester les capacités des systèmes d’aide au classement tarifaire douanier à trouver les bons codes du SH, chaque produit présentant son lot de difficultés pour ces systèmes. Nous avons traduit la liste en portugais et avons testé le CLASSIF sur la base des produits mentionnés. Les résultats sont reproduits dans le Tableau 1. Il est important de mentionner que le CLASSIF a été programmé pour suggérer des codes à huit chiffres lorsque la qualité du résultat est considérée comme étant élevée, et des codes à quatre chiffres lorsqu’elle est faible.
À chaque fois que le CLASSIF a proposé un code à huit chiffres, le résultat était correct et le code correct était celui proposé par le système comme ayant la plus grande probabilité d’exactitude (première suggestion). Cela a été le cas dans six essais sur dix. À trois reprises, le CLASSIF a proposé un code correct à quatre chiffres, certes non pas comme premier résultat le plus probable mais, tout du moins, jamais parmi plus de dix solutions alternatives. Le CLASSIF n’a échoué complètement qu’à une seule occasion. Nous avons retrouvé la cause du problème (la présence de données « poubelles » dans la base de connaissances du SISAM qui seront bientôt supprimées) et il devrait être résolu sous peu.
Comment le Brésil a transformé ses contrôles douaniers grâce à l’intelligence artificielle et d’autres technologies
Par Jorge Jambeiro Filho, responsable innovation et intelligence artificielle, Gustavo Lacerda Coutinho, responsable de la coordination spéciale aux fins de la gestion des risques douaniers, et Kelly Morgero, cheffe du département des arrangements de reconnaissance mutuelle du Centre des opérateurs économiques agréés, Douane brésilienne
Les systèmes informatiques douaniers au Brésil se sont profondément transformés au cours des dernières années, redéfinissant la façon dont l’administration des douanes gère et atténue les risques. À travers une utilisation novatrice de l’intelligence artificielle, notamment de l’apprentissage automatique et de la technologie de la surveillance en temps réel, le Brésil a pu améliorer sa capacité à détecter les transactions suspectes et sa réponse aux menaces, renforçant par là même l’intégrité des opérations commerciales internationales. Le présent article passe en revue les progrès réalisés, les défis et les perspectives futures associés à ces outils de gestion des risques.
Il y a six ans, le Brésil décrivait pour la première fois dans un article paru dans OMD Actualités ses solutions de gestion des risques intégrée. À l’époque, l’accent avait été mis sur trois systèmes principaux. Le premier était le SISAM[1], un système d’apprentissage automatique qui analyse les déclarations d’importation en tirant parti des données historiques pour estimer les probabilités associées à quelque 30 types d’erreurs. Le deuxième était ANIITA[2], un système d’intégration et d’expertise qui offre aux douaniers une vision uniforme et cohérente des transactions en combinant les informations de diverses bases de données et en appliquant des règles définies par les êtres humains pour générer des alertes, simplifiant ainsi les processus décisionnels. Le troisième était PATROA, un système de surveillance en ligne qui repose sur la réactivité en temps réel et qui envoie donc des courriels et des messages instantanés aux douaniers lorsqu’une transaction douteuse est détectée, leur permettant ainsi d’agir immédiatement en conséquence, si nécessaire.
Ensemble, ces solutions ont permis à la Douane de moderniser rapidement ses procédures de contrôle et ont joué un rôle décisif pour en améliorer l’efficacité et le rendement. Ces outils ont tous évolué entre-temps et, aujourd’hui, ils constituent des composants essentiels pour la gestion des activités en douane au Brésil.
ANIITA et PATROA sont passés par d’importantes mises à niveau, mais c’est surtout au niveau du SISAM que les fonctionnalités ont le plus évolué. Par ailleurs, de nouveaux systèmes ont été mis au point pour renforcer encore la capacité du pays à gérer et à surveiller le commerce international et la circulation des voyageurs.
Le SISAM : passer au crible les déclarations d’importation avec plus de précision
Le système de sélection douanière par le biais de l’apprentissage automatique, plus connu sous son acronyme de SISAM, a joué un rôle déterminant dans l’analyse de toutes les déclarations d’importation au Brésil au cours de la dernière décennie. Il s’est avéré être particulièrement utile pour détecter plusieurs types d’erreurs, dont le plus important est le classement erroné des marchandises. Pour s’assurer d’utiliser les dernières avancées technologiques, le Brésil a récemment apporté quelques changements à l’outil.
Le système se fonde sur un apport de données exhaustives pour contrôler les opérations d’importation. Il recueille et analyse les renseignements tirés de la déclaration d’importation soumise par le biais du Système de gestion du commerce international intégré (Siscomex) du Brésil. Basé sur l’IA, l’outil « apprend » sur la base de l’historique des déclarations d’importation à travers un apprentissage tant supervisé que non supervisé, deux méthodes dans le cadre desquelles des algorithmes peuvent analyser un jeu de données et en extraire des constatations utiles.
Lorsque des incohérences sont détectées durant le dédouanement et que des corrections sont apportées à la déclaration d’importation, la version rectifiée de la déclaration est également envoyée au SISAM dans le but qu’il puisse établir les corrélations directes entre la présence ou l’absence d’erreurs et relever les schémas éventuels qui se dégagent en fonction des attributs de la déclaration (apprentissage supervisé).
Les déclarations portant sur les importations qui ont été dédouanées sans avoir fait l’objet d’une vérification sont utilisées aux fins de l’apprentissage non supervisé et permettent de faire l’inventaire des tendances typiques et atypiques. Le meilleur exemple de ce processus de détection des données aberrantes (atypiques) a trait aux incompatibilités entre la description des marchandises en langage naturel et leur code de nomenclature déclaré. Le système s’intéresse aussi aux produits jugés « inhabituels » pour une société enregistrée sous un certain code d’activité économique et aux marchandises achetées auprès de fournisseurs ou de fabricants qui ne vendent généralement pas ce type d’articles aux autres importateurs brésiliens.
Toutefois, au niveau des modes opératoires, l’un des problèmes du SISAM était qu’il n’exploitait ni les avis d’infraction qui sont émis lorsque des infractions sont constatées après le dédouanement (la déclaration d’importation n’étant dans ce cas pas corrigée), ni les rapports d’experts, ni les décisions anticipées. Pour combler cette lacune, le SISAM a récemment été intégré à divers systèmes stockant ce genre d’’informations. Cela a permis de lancer une procédure dite de « rectification virtuelle ». Les déclarations officielles ne sont jamais vraiment rectifiées, en réalité, mais les renseignements font désormais partie de la base de connaissances du SISAM.
Le SISAM fonctionne sur la base d’un modèle pleinement bayésien qui met à jour les probabilités en recourant aux nouveaux éléments de preuve sans passer par un entraînement complet. Dans le cadre des activités douanières, un tel modèle permet au système d’affiner ses prévisions et son processus décisionnel au fur et à mesure qu’il reçoit plus de données, ce qui lui permet de réagir promptement face à de nouveaux cas de fraude. L’autre force du SISAM est sa capacité à gérer les descriptions incorrectes de marchandises. À ce titre, le SISAM suit deux modalités.
D’abord, il met en corrélation le code de classement tarifaire correct avec la description initialement soumise. Cette approche permet au SISAM de se familiariser avec les erreurs et les imprécisions que l’on retrouve le plus couramment dans les déclarations. Par exemple, si le mot « plastique » ne devrait apparaître en principe que rarement dans la description d’un produit correspondant à un code de classement de la Nomenclature commune du Mercosur (NCM) en lien avec le caoutchouc, le SISAM prend toutefois note du fait que, dans la pratique, ces incohérences sont plus courantes qu’on ne pourrait le croire.
Ensuite, le SISAM tient compte d’une série de facteurs complémentaires, au-delà de la description des marchandises, notamment de ce que l’importateur est censé acheter, de ce que le fournisseur est censé vendre, des erreurs dans les codes de classement tarifaire qui ont été détectées par le passé, des erreurs de désignation qui ont été constatées par le passé, de qui les a commises et des périodes durant lesquelles elles se sont produites. En analysant ces tendances et ces schémas, le SISAM peut prédire les incohérences potentielles, relever les anomalies avec plus de précision et tirer la sonnette d’alarme sur les transactions douteuses.
Pour établir des tendances pertinentes concernant un importateur, le SISAM fait fond sur l’historique de toutes les déclarations, qu’elles aient donné lieu à une inspection ou pas, ainsi que sur l’historique des déclarations d’autres importateurs, tout en excluant délibérément les déclarations de l’importateur visé n’ayant pas fait l’objet d’une vérification. La capacité du système à exclure les données non vérifiées de l’importateur en cause est essentielle car, sinon, les erreurs que ce dernier aurait pu commettre de manière répétée pourrait induire le SISAM en erreur en lui faisant croire que le comportement « erroné » est correct. Le SISAM supprime ce biais à la volée, ce dont il est capable grâce à son approche de modélisation pleinement bayésienne.
Même si l’exercice s’annonce difficile, un plan minutieux est déjà en place pour utiliser l’apprentissage profond et les grands modèles linguistiques (LLM) afin de traiter les descriptions de produits dans le SISAM sans compromettre les avantages évoqués plus haut.
De plus, l’outil devra être ajusté pour tenir compte d’un changement majeur intervenu dans la façon dont les importateurs décrivent les marchandises. Comme nous l’avions déjà expliqué dans le n° 103 de l’OMD Actualités, un catalogue décrivant les marchandises sur la base d’attributs prédéfinis a été incorporé au SISCOMEX. Le Catalogue de produits (CP) permet à l’importateur de décrire les caractéristiques des marchandises de manière normalisée, en utilisant des champs structurés. Ce système permet de réutiliser les informations pour de futures transactions, de réduire le nombre d’erreurs éventuellement commises lorsque l’importateur remplit ses déclarations et d’accélérer l’analyse des opérations. L’utilisation du catalogue est en passe de devenir obligatoire. Pour profiter pleinement des possibilités qu’ouvrent les champs structurés, nous devrons modifier les modèles d’apprentissage automatique du SISAM. Ces changements sont en cours de développement.
Le SISAM a été conçu pour détecter les erreurs au niveau des codes de classement des marchandises et non pour aider les importateurs et les exportateurs bien intentionnés à classer leurs produits. À cette fin, un nouveau système a été créé : le CLASSIF[3]. Ce système analyse la classification des marchandises en se basant sur la Nomenclature commune du Mercosur (NCM), qui se fonde elle-même sur les codes du Système harmonisé de désignation et de codification des marchandises (SH), mais en y ajoutant deux chiffres supplémentaires. Les importateurs et exportateurs peuvent saisir la description d’un produit dans le système et ce dernier leur montre alors des renseignements tels que le code NCM et son libellé, les notes légales s’y rapportant ainsi que les Notes explicatives pertinentes du Système harmonisé de l’OMD, les décisions anticipées concernant ce code et, enfin, des propositions de classement émanant directement du SISAM.
Nous avons d’ailleurs adapté le SISAM afin qu’il estime les probabilités uniquement sur la base de la description des marchandises donnée par les utilisateurs, en contournant les autres attributs qu’il utilise normalement. Cette approche affaiblit quelque peu le modèle mais l’avantage est qu’elle ne montre pas aux utilisateurs comment tromper le SISAM. Même si un importateur mal intentionné venait à changer constamment la description d’un produit jusqu’à ce que le CLASSIF lui suggère le code qu’il souhaite utiliser, le SISAM ne manquera pas de détecter l’erreur plus tard dans le processus. Le résultat concernant les importateurs reste satisfaisant.
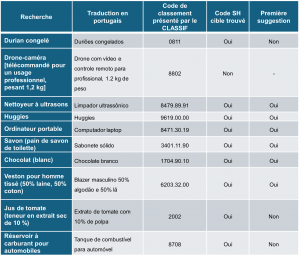
Un article publié récemment dans le World Customs Journal[4] présente une liste de marchandises à utiliser afin de tester les capacités des systèmes d’aide au classement tarifaire douanier à trouver les bons codes du SH, chaque produit présentant son lot de difficultés pour ces systèmes. Nous avons traduit la liste en portugais et avons testé le CLASSIF sur la base des produits mentionnés. Les résultats sont reproduits dans le Tableau 1. Il est important de mentionner que le CLASSIF a été programmé pour suggérer des codes à huit chiffres lorsque la qualité du résultat est considérée comme étant élevée, et des codes à quatre chiffres lorsqu’elle est faible.
Tableau 1 : Tests menés sur le CLASSIF sur la base des exemples tirés d’un article publié dans le World Customs Journal
| Recherche | Traduction en portugais | Code de classement présenté par le CLASSIF | Code SH cible trouvé | Première suggestion |
| Durian congelé | Duriões congelados | 0811 | Oui | Non |
| Drone-caméra [télécommandé pour un usage professionnel, pesant 1,2 kg] | Drone com vídeo e controle remoto para profissional, 1.2 kg de peso | 8802 | Non | – |
| Nettoyeur à ultrasons | Limpador ultrassônico | 8479.89.91. | Oui | Oui |
| Huggies | Huggies | 9619.00.00. | Oui | Oui |
| Ordinateur portable | Computador laptop | 8471.30.19. | Oui | Oui |
| Savon (pain de savon de toilette) | Sabonete sólido | 3401.11.90. | Oui | Oui |
| Chocolat (blanc) | Chocolate branco | 1704.90.10. | Oui | Oui |
| Veston pour homme tissé (50% laine, 50% coton) | Blazer masculino 50% algodão e 50% lã | 6203.32.00. | Oui | Oui |
| Jus de tomate (teneur en extrait sec de 10 %) | Extrato de tomate com 10% de polpa | 2002 | Oui | Non |
| Réservoir à carburant pour automobiles | Tanque de combustível para automóvel | 8708 | Oui | Non |
À chaque fois que le CLASSIF a proposé un code à huit chiffres, le résultat était correct et le code correct était celui proposé par le système comme ayant la plus grande probabilité d’exactitude (première suggestion). Cela a été le cas dans six essais sur dix. À trois reprises, le CLASSIF a proposé un code correct à quatre chiffres, certes non pas comme premier résultat le plus probable mais, tout du moins, jamais parmi plus de dix solutions alternatives. Le CLASSIF n’a échoué complètement qu’à une seule occasion. Nous avons retrouvé la cause du problème (la présence de données « poubelles » dans la base de connaissances du SISAM qui seront bientôt supprimées) et il devrait être résolu sous peu.
Aide au contrôle a posteriori (CAP)
Le SISAM a initialement été mis au point pour venir en aide à la sélection des déclarations d’importation à des fins de contrôle dans les zones primaires. Toutefois, ses rapports de risque peuvent être regroupés de diverses manières, notamment par entreprise ou par classement tarifaire. Ces agrégations de données peuvent être utiles pour les équipes chargées de procéder à des CAP et elles contribuent en outre à déplacer les contrôles douaniers vers la phase après dédouanement, dans la lignée des accords de facilitation des échanges. À l’heure actuelle, au lieu de développer des mécanismes d’agrégation dans le SISAM, nous avons choisi d’incorporer dans notre lac de données les rapports individuels du SISAM qui peuvent être agrégés grâce à des logiciels comme Power BI CONTÁGII[5], ANALYTICS[6], Jupyter Notebook, HUE et SPARK.
Mettre à contribution les enseignements tirés pour développer de nouveaux systèmes
Par ailleurs, plusieurs nouveaux systèmes ont été mis au point pour renforcer encore la capacité du Brésil à gérer et à contrôler le commerce international et le mouvement des voyageurs.
Un environnement de guichet unique
Le Brésil est en train de mettre au point un nouveau système de guichet unique pour le commerce extérieur, baptisé Portal Único do Comércio Exterior (PUCOMEX).[7] Ce système uniformise et centralise le traitement des documents commerciaux, offrant des avantages importants aux opérateurs, notamment des économies de temps et de coût pour leurs activités transfrontalières. Quant à la Douane, PUCOMEX offre d’énormes possibilités aux fins de la supervision et de la gestion des flux commerciaux internationaux. La plateforme centralisée permet de garantir un suivi efficace et d’améliorer la coordination entre les divers organismes gouvernementaux impliqués dans les contrôles douaniers et frontaliers.
La mise au point de PUCOMEX a été modelée sur les expériences concluantes de développement en interne de logiciels douaniers comme ANIITA et PATROA. Bien que PUCOMEX ait été créé par une société externe, Serpro (Service fédéral de traitement des données), il fait en grande partie fond sur les connaissances et l’expertise acquises durant les projets douaniers susmentionnés. L’approche adoptée s’est révélée extrêmement bénéfique puisqu’elle permet de mener des tests en toute flexibilité avant de passer à un système plus robuste, une entreprise spécialisée s’occupant du développement et de la maintenance de la nouvelle plateforme.
Intégrer les systèmes de la Douane et des compagnies aériennes pour contrôler les passagers
Notre système de contrôle des voyageurs est aujourd’hui intégré aux systèmes des compagnies aériennes et évalue les risques en fonction de la situation économique des passagers, de l’itinéraire choisi, des déplacements précédents et des compagnons de voyage non déclarés mais répétés[8],[9]. Des outils de reconnaissance faciale sont également utilisés dans les aéroports et ils sont directement connectés aux systèmes douaniers.
Surveiller les véhicules
Un système baptisé SIVANA se charge de surveiller les véhicules près des frontières terrestres du Brésil en utilisant les images prises par les caméras de surveillance du réseau routier. Il permet aux douaniers d’analyser les itinéraires suivis précédemment par les véhicules ciblés et de recevoir des informations en temps réel sur leur localisation, ce qui leur permet de réagir immédiatement en cas de menace potentielle, en particulier lorsqu’il s’agit de trafic de drogues et de commerce de produits de contrefaçon.
Pour renforcer les capacités de SIVANA, et plus spécifiquement le relevé des tendances et des anomalies qui pourraient indiquer des activités illicites aux frontières terrestres du pays, nous avons conclu un partenariat avec Itaipu Parquetec, un parc d’innovation composé d’entités telles que des institutions éducatives, des entreprises et des organismes gouvernementaux. L’objectif est de développer une application, appelée SMART WALL, en utilisant l’analyse bayésienne et l’apprentissage profond.
Garantir la cohérence des données dans tous les documents commerciaux
Autre exemple de technologie novatrice, le système BATDOC[10] a été créé pour comparer les déclarations d’importation (qui sont des documents électroniques conçus pour être compris par un ordinateur) avec les documents justificatifs qui sont encore soumis sous la forme de documents numériques ou d’images scannées de documents originaux tels que des factures ou des connaissements. Ce système permet de garantir la cohérence des données dans tous les documents. Grâce à la technologie de reconnaissance optique de caractères (OCR), le BATDOC compare automatiquement des renseignements primordiaux comme le nom et l’adresse des parties impliquées, ainsi que la quantité et la valeur des marchandises. En croisant les documents, le BATDOC contribue à contrôler les erreurs et les incohérences, renforçant ainsi l’exactitude et la fiabilité des informations.
Tirer parti de l’expertise externe pour automatiser l’analyse des images radiographiques
L’une des limites du SISAM est son incapacité à incorporer des images radiographiques à son analyse. Le projet AJNA a justement été lancé pour combler cette lacune. AJNA[11] est un système piloté par un réseau de neurones artificiels d’apprentissage profond qui recueille des images radiographiques, les affichent et les analyse de manière automatisée.
Au début, AJNA n’a été déployé qu’au port de Santos, l’un des plus grands d’Amérique latine. Le système gérait des processus tels que la collecte d’images depuis les scanners des entrepôts sous douane, le stockage centralisé et normalisé de ces images et leur recadrage pour isoler les conteneurs des camions les transportant. De plus, AJNA pouvait détecter des marchandises dans des conteneurs qui étaient supposés être vides.
À l’instar du SISAM, AJNA a initialement été conçu pour être développé et maintenu par une équipe interne. Toutefois, si le SISAM était le seul projet d’intelligence artificielle en cours de développement à l’époque, AJNA a été lancé en même temps que 40 autres projets en lien avec l’intelligence artificielle. Très vite il s’est avéré indispensable de faire appel à des experts externes pour développer encore l’application. Deux projets sont actuellement en cours avec des entreprises privées à cet effet.
Utiliser les images radiographiques pour détecter les erreurs de classement
Le premier de ces projets, appelé X-Class, vise à utiliser les images à rayons X pour détecter les erreurs de classement. Nous avons choisi de travailler avec une startup, car nous sommes convaincus que seul un modèle d’apprentissage profond méticuleusement conçu peut gérer les particularités du projet d’une part, et, d’autre part, parce que nous disposons de millions d’images et des déclarations d’importation correspondantes pour entraîner le modèle.
La tâche est complexe, ne fût-ce qu’en raison de l’existence de plus de 10 000 codes. Si certains de ces codes correspondent à des articles qui produisent des tracés bien distincts et facilement reconnaissables dans les images radiographiques, d’autres portent sur des marchandises qui donnent des images assez ressemblantes. Pour compliquer encore la tâche des douaniers, un même conteneur peut transporter différents types de biens et, à l’écran, les motifs se superposent et sont difficiles à distinguer. Le fait que l’on ne peut utiliser qu’un seul faisceau de rayons X ne fait qu’exacerber le problème et il devient dès lors encore plus difficile de séparer et d’identifier les diverses marchandises placées dans un même conteneur.
Heureusement, le SISAM enverra les résultats de l’analyse de classement à X-Class, ce qui permettra de réduire considérablement le nombre de codes probables. X-Class sera encore incapable de reconnaître un produit dans certains cas mais, au moins, il éliminera les suggestions du SISAM qui seront incompatibles avec les images observées.
Mettre Google Gemini à contribution pour analyser les images des petits colis et des bagages des voyageurs
Le deuxième projet porte sur les petits colis et les bagages des voyageurs. Pour contribuer à l’analyse des images scannées, nous avons décidé d’exploiter le modèle Google Gemini. Cet outil est pré-entraîné et multimodal, c’est-à-dire qu’il est capable de traiter et d’analyser bien plus que du texte. Lorsqu’une image lui est soumise, Gemini peut la décrire ou répondre à des questions portant sur son contenu, en résumer le contenu et faire des extrapolations sur la base de ce même contenu.
Il n’est donc plus nécessaire d’utiliser des données pour entraîner le modèle. À la place, les douaniers doivent poser des questions au système en portugais. Deux types de questions peuvent être posées. Les agents peuvent demander à la machine de détecter un article prédéfini comme de la drogue, des armes ou des produits fabriqués à partir d’espèces sauvages. Ils demanderont par exemple : « ce bagage contient-il de la drogue ? » ou « ce colis contient-il quoi que ce soit qui ressemble à un squelette d’oiseau ? ». Les questions du second type sont plus sophistiquées et peuvent être utilisées pour détecter les cas de fraude fiscale, comme par exemple : « ce paquet contient-il quoi ce que ce soit qui ne correspond pas à la description fournie, qui était… ? »
À ce jour, seules les questions du premier type ont été testées. Les résultats sont prometteurs. Les images radiographiques des petits colis sont bien plus claires que celles des conteneurs et parlent souvent d’elles-mêmes, réduisant ainsi le besoin d’intégration avec d’autres outils analytiques.
Conclusion
Le recours à l’intelligence artificielle, qui était encore une nouveauté il y a peu, s’est généralisé au sein de la Douane du Brésil. Les résistances initiales, dues à l’incertitude et au scepticisme, ont été surmontées et ont ouvert la voie à une demande massive de solutions dans le domaine informatique. Notre modèle de développement initial, fondé autour d’une équipe interne uniquement, a dû être élargi pour inclure des partenaires tels que des universités, des parcs d’innovation, des grandes plateformes technologiques, des startups et le Service fédéral de traitement des données du Brésil. Nous sommes encore en train d’apprendre à gérer cette nouvelle réalité.
L’intelligence artificielle ne se balade pas dans l’espace. Elle doit être reliée à un vaste écosystème technologique qui inclut différents outils de collecte de données, des bases de données multiples, des outils de visualisation de données, des systèmes d’alerte en temps réel, des systèmes hérités, des nouveaux systèmes internes, des systèmes gouvernementaux en dehors du Secrétariat fédéral des recettes du Brésil et des systèmes d’entreprises privées. Ces intégrations représentent souvent une part significative des travaux de développement.
Nos systèmes d’intelligence artificielle apprennent des êtres humains sans essayer de les remplacer pour autant, et toutes les décisions qu’ils prennent sont passées au crible par des personnes. En fonction des possibilités, nos systèmes offrent des explications qui nous aident dans l’examen de ces décisions.
L’intelligence artificielle est devenue un outil indispensable pour gérer les complexités du commerce moderne. Si des résultats importants ont été obtenus, notamment un traitement plus précis et efficace des données de transaction, elle offre encore un vaste potentiel à exploiter.
En savoir +
jorge.jambeiro@rfb.gov.br
gustavo.coutinho@rfb.gov.br
kelly.morgero@rfb.gov.br
[1] Jambeiro Filho, Jorge. Artificial Intelligence in the Customs Selection System through Machine Learning (SISAM). Prêmio de Criatividade e Inovação da RFB, 2015 (Prix de la créativité et de l’innovation du RFB 2015). https://www.jambeiro.com.br/jorgefilho/sisam_mono_eng.pdf
[2] Coutinho, Gustavo. Aniita – uma abordagem pragmática para o gerenciamento de risco aduaneiro baseada em software. Prêmio de Criatividade e Inovação da RFB, 2012 (Prix de la créativité et de l’innovation du RFB 2015). http://repositorio.enap.gov.br/handle/1/4607
[3] Domingues, Luiz Henrique; Navarro, Claudia Elena Figueira Cardoso; Steckel, Carlos Humberto; Lima, Lucas Araújo de; Casado, Marco Antônio Rodrigues. Prêmio de Criatividade e Inovação da RFB, 2023 (Prix de la créativité et de l’innovation du RFB 2015). https://ea.ufba.br/wp-content/uploads/2023/11/E-book-A_22-premio_16_abr24.pdf
[4] Grainger, Andrew. Customs Tariff Classification and the Use of Assistive Technologies. World Customs Journal, 2024.
[5] Figueredo, Gustavo Henrique Britto. Um novo paradigma na auditoria em meio digital. Prêmio de Criatividade e Inovação da RFB, 2010 (Prix de la créativité et de l’innovation du RFB 2015). https://repositorio.enap.gov.br/handle/1/4580
[6] Receita Federal do Brasil. Receita Federal apresenta ferramentas de gerenciamento de riscos em evento informal da OCDE na Suécia. 2024.
[7] Corbari, Jackson Aluir; Zambrano, Alexandre da Rocha; Morgero, Kelly Cristina Silva. Portal Único Siscomex: A transformação digital no comércio exterior brasileiro. 2024.
https://alfandegas.cplp.org/Newsletter/Documents/Newsletter%208%20janeiro%202024_VF.pdf
[8] Moraes, Felipe Mendes. Sistema e-DBV – Módulo viajante único, 2017. https://repositorio.enap.gov.br/handle/1/4635
[9] Thompson, Ronald Cesar. Projeto IRIS – Reconhecimento facial de viajantes. 2016. https://repositorio.enap.gov.br/handle/1/4627
[10] Barbosa, Diego de Borba. Batimento Automatizado de Documentos na Importação – BatDoc. Prêmio de Criatividade e Inovação da RFB, 2016 (Prix de la créativité et de l’innovation du RFB 2015). http://repositorio.enap.gov.br/handle/1/4630
[11] Brasílico, Ivan. AJNA – Plataforma de Visão Computacional e Aprendizado de Máquina. Prêmio de Criatividade e Inovação da RFB, 2017 (Prix de créativité et de l’innovation du RFB 2015). https://repositorio.enap.gov.br/jspui/handle/1/4634