

Apprentissage automatique
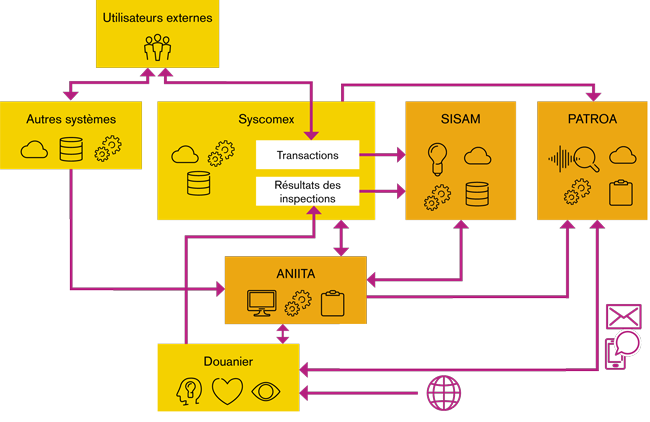
Le RFB s’est doté d’un outil d’intelligence artificielle (IA), baptisé SISAM, acronyme portugais signifiant « système de sélection douanière par apprentissage automatique ». Cet outil informatique est utilisé depuis août 2014 pour évaluer les risques posés par les importations. Actif 24 heures sur 24 et 7 jours sur 7, l’outil « s’instruit » en utilisant l’historique des déclarations à l’importation, par le biais tant de l’apprentissage supervisé que de l’apprentissage non supervisé, deux méthodes permettant à la machine (ou plus précisément à l’algorithme dont elle est équipée) de traiter un jeu de données dans le but d’en « apprendre » quelque chose d’utile.
Avec l’apprentissage supervisé, le résultat escompté par le biais de l’algorithme est déjà connu et l’algorithme « apprend » grâce à un jeu de données de formation qui contient toutes les réponses correctes. Aux fins de cette « formation », les déclarations d’importations qui ont été contrôlées par les douaniers sont utilisées pour relever les corrélations directes entre la présence ou l’absence d’erreurs et pour dégager les tendances compte tenu des informations contenues dans la déclaration telles que :
Les déclarations portant sur les importations qui ont été dédouanées sans avoir fait l’objet d’une vérification sont utilisées aux fins de l’apprentissage non supervisé et permettent l’identification de tendances typiques et atypiques. Le meilleur exemple de ce processus de détection des données aberrantes (atypiques) a trait aux incompatibilités entre la description des marchandises en langage naturel et leur code de nomenclature déclaré. Les produits jugés « inhabituels » pour une société portant un certain code d’activité économique ou encore les marchandises achetées auprès de fournisseurs ou de fabricants qui ne vendent généralement pas ce type d’articles aux autres importateurs brésiliens attirent également l’attention du système.
Dans la pratique, les capacités d’apprentissage supervisé et non supervisé du SISAM ne sont pas séparées. Elles émanent toutes deux des mêmes modèles probabilistes et se fondent sur la même base de connaissances qui contient les données associées à 8,5 milliards de tendances différentes. En se référant aux données relatives à un produit individuel pour chaque déclaration à l’importation enregistrée, le SISAM est à même de calculer les probabilités d’irrégularité pour quelque 30 types d’erreurs.
Ces erreurs comprennent notamment les fausses désignations de marchandises, les erreurs dans les codes de la nomenclature, les erreurs dans les pays d’origine déclarés, l’absence de licences d’importation, les régimes fiscaux non applicables, les demandes erronées de traitement tarifaire préférentiel ou de traitement « ex-tarifaire » (régime qui permet aux entreprises brésiliennes de réduire leur charge fiscale lorsqu’elles importent des machines, appareils ou pièces qui ne sont pas fabriqués au Brésil et ne peuvent donc pas être remplacés par les producteurs locaux), ou tout simplement, l’utilisation de taux erronés pour le calcul des droits d’importation, de la taxe sur les produits finis, des contributions sociales et des droits anti-dumping.
Pour chaque donnée déclarée potentiellement erronée, le SISAM calcule toutes les données alternatives et évalue l’incidence de ces changements sur les taxes et sur les obligations administratives. Le SISAM calcule ensuite le rendement attendu pour chaque inspection possible durant le processus de dédouanement. Ces résultats sont ensuite utilisés pour « alimenter » la théorie des décisions et la théorie des jeux qui sous-tendent toutes deux le mécanisme de sélection du SISAM.
Le SISAM a la capacité d’expliquer, en « langage naturel » (expression utilisée pour se référer au langage humain dans le domaine de l’IA), les raisons pour lesquelles un envoi de marchandises a été sélectionné pour vérification et de fournir les détails sur la façon dont il a calculé les probabilités en matière de risque. Ces explications permettent aux douaniers d’évaluer l’analyse effectuée par le système et de décider s’ils veulent suivre ses recommandations ou pas. Si la décision finale de contrôler l’envoi leur revient, les douaniers peuvent tirer parti de la capacité du système à déceler des infractions qui seraient certainement passées inaperçues parmi les milliers de déclarations d’importation.
En outre, la base de connaissances du SISAM peut être mise à jour sans cesse, ce qui lui permet d’apprendre à partir des déclarations d’importation soumises chaque jour sans avoir à être « formé » à nouveau. Le processus d’apprentissage peut également être distribué sur plusieurs machines et les bases de connaissances en résultant peuvent être cumulées et ajoutées par la suite. La base de connaissances du SISAM permet même de séparer certaines informations d’autres renseignements, comme par exemple, l’évaluation du comportement d’un importateur par rapport à toutes les informations dans la base, à l’exception des renseignements fournis par l’importateur lui-même. De cette manière, le SISAM évite d’être induit en erreur par un importateur et amené à conclure qu’un certain comportement est correct juste parce qu’il est récurrent.
De plus, le SISAM dispose des ressources nécessaires pour gérer les « classes mutantes », c’est-à-dire les classes cibles dont les définitions peuvent changer, ce qui est atypique pour les systèmes d’apprentissage supervisé mais nécessaire puisque les règles de classification des marchandises changent souvent. Si un code de la nomenclature est fractionné en deux, par exemple, les données sur les codes nouvellement créés resteront exceptionnelles pendant un certain temps. Le SISAM peut utiliser les anciennes données, qui sont beaucoup plus nombreuses, pour isoler les deux nouveaux codes des 10.000 autres codes dans le tableau de la nomenclature puis séparer les deux codes l’un de l’autre, et ainsi utiliser les anciennes déclarations portant sur ces marchandises pour analyser les nouvelles.
Lorsqu’il analyse une déclaration d’importation qui vient d’être déposée, le SISAM tient également compte du fait que les modèles de comportement changent avec le temps. Le système est aussi parfois utilisé pour analyser d’anciennes déclarations d’importation, puisqu’elles peuvent être réexaminées après le dédouanement. Toute analyse d’une déclaration d’importation s’effectue en tenant compte des tendances qui prévalent à la date exacte de dépôt.
Lors des premières présentations du SISAM aux douaniers, ces derniers se sont montrés plus sceptiques qu’enthousiastes bien que les essais menés aient déjà prouvé l’efficacité du système. Ils ont vite changé d’avis une fois que le dispositif a commencé à envoyer des résultats tout en expliquant le raisonnement étayant ses suggestions en matière de sélection. Après avoir suivi une formation, les fonctionnaires se sont approprié le système et, aujourd’hui, ils décident de vérifier une transaction sur la base des suggestions du SISAM dans 30% des cas.
Une description plus détaillée des innovations techniques qui ont contribué à la mise au point du SISAM, les résultats statistiques démontrant la précision de ses prédictions ainsi que des exemples d’explications en langage naturel qu’il génère peuvent être consultés en ligne (voir références en bas de page).
Exploiter les connaissances des douaniers
Les bases de données Siscomex ne peuvent rassembler toutes les connaissances que les douaniers accumulent avec l’expérience. Ces derniers ont à leur disposition d’autres bases de données dont les informations peuvent entrer en ligne de compte dans les décisions qu’ils prennent. Ils approfondissent aussi leurs connaissances en regardant, en touchant, voire en sentant les marchandises ainsi qu’en associant mentalement leurs observations avec les données disponibles sous format électronique. Ils s’entretiennent également avec les importateurs, lisent la documentation spécialisée et les rapports techniques sur les produits et effectuent régulièrement des recherches sur internet pour obtenir davantage d’informations.
S’il n’existe malheureusement pas de méthode pour accéder directement au cerveau humain afin de garantir que toutes ces connaissances soient disponibles au bon moment et au bon endroit, le Brésil a mis au point un système qui tente de se rapprocher de cette idée. C’est ainsi que l’Analyseur intelligent et intégré des transactions douanières, plus connu sous son acronyme portugais d’ANIITA, est né.
La mise au point d’ANIITA a commencé en 2011 au point de passage frontalier d’Uruguaiana. À l’époque, pour évaluer les risques d’une déclaration à l’importation, les douaniers devaient consulter au moins sept systèmes différents, dont Siscomex. Chaque système fournissait des données différentes, telles que les licences de commerce international des entreprises, par exemple, leur historique commercial, leur profil en matière de recettes fiscales (y compris les données chiffrées telles que les revenus bruts et le nombre d’employés), ainsi que les informations soumises par des administrations douanières étrangères.
ANIITA extrait les données de ces différents systèmes et présente les informations les plus importantes aux fins du dédouanement et de l’évaluation des risques sur un seul et même écran. Le dispositif permet ainsi aux utilisateurs de gagner énormément de temps dans la mesure où ils ne doivent plus naviguer dans plusieurs systèmes manuellement.
ANIITA peut également traiter les données et relever les incohérences et les menaces connues en croisant les données et avoir recours aux méthodes heuristiques, c’est à dire de recherche empirique, fondées sur l’approche progressive d’un problème donné, en vue d’en trouver la solution. Le logiciel permet aux utilisateurs de créer des règles fondées sur leurs propres connaissances des risques et est devenu par ce biais un « système expert ». Les douaniers peuvent saisir de nouvelles règles selon le profil de risque des entreprises, des personnes, des marchandises et d’une combinaison complexe d’attributs. ANIITA est une application de bureau mais la base de données où les données et les règles à appliquer sont entreposées est centralisée. Cet agencement permet de partager les données et les règles avec tous les employés de l’organisation et les connaissances d’un individu peuvent donc être disséminées, par ce biais, à l’ensemble du personnel chargé de l’évaluation des risques en matière douanière.
De plus, ANIITA utilise les données disponibles dans le système INDIRA qui offre aux pays membres du MERCOSUR un accès électronique aux données portant sur toutes les exportations et importations. L’outil permet ainsi de croiser les données de chaque déclaration d’exportation en provenance des pays du MERCOSUR avec la déclaration d’importation correspondante au Brésil. ANIITA est à même de déceler les incohérences dans les déclarations et de détecter, par exemple, les cas où le classement de marchandises à l’exportation ne correspond pas au classement des marchandises à l’importation. Soit dit en passant, voilà un exemple concret de mise en œuvre par le Brésil du concept de douanes en réseau international tel que mis au point par l’OMD.
ANIITA a été adopté spontanément par presque toutes les unités douanières au Brésil et est devenu au final un système intégré, dont l’utilisation est devenue obligatoire pour tous les fonctionnaires ayant des pouvoirs décisionnels concernant la vérification éventuelle de marchandises. Conçu au départ principalement pour traiter les déclarations à l’importation, il a très vite pu être élargi aux envois de courrier express, aux envois postaux et aux déclarations à l’exportation. ANIITA offre aussi à présent différents niveaux de privilèges aux usagers, permettant à certains d’entre eux de créer des règles pouvant être appliquées au niveau national immédiatement.
Système de surveillance
Lancé en décembre 2017, le Système de surveillance des opérations douanières en temps réel PATROA vient compléter l’écosystème informatique actuel du Brésil consacré à la gestion des risques douaniers. Tout comme ANIITA, PATROA accepte les règles créées par les humains mais, au lieu d’agir uniquement à la demande d’un usager, il fonctionne côté serveur et applique les règles aux transactions dès qu’elles sont saisies dans le système, permettant ainsi d’appliquer les profils de risque en temps réel.
De plus, PATROA peut recourir à ANIITA et au SISAM afin d’obtenir leurs analyses détaillées d’une transaction et décider ensuite d’alerter un fonctionnaire par courriel ou par message instantané sur son téléphone portable. Le fonctionnaire peut alors y répondre et arrêter la transaction sur-le-champ, si besoin est. PATROA peut également décider de ne pas faire appel à un douanier immédiatement et, à la place, de commencer à sauvegarder des informations complémentaires sur les transactions connexes et d’élaborer un rapport qui ne sera envoyé que par la suite à un être humain. Ces rapports peuvent décrire, par exemple, un comportement non conforme de la part d’un opérateur économique agréé (OEA).
Conclusion
Le présent article s’est penché sur trois systèmes douaniers mis au point par le RFB et sur la façon dont ils interagissent et se complètent mutuellement afin de fournir au pays un dispositif solide de gestion des risques. Les trois systèmes évoluent constamment afin de gagner en précision et de pouvoir traiter un nombre accru de types de transactions et d’infractions. Ils interagissent bien, par ailleurs, avec les systèmes de renseignement du service des recettes fiscales qui sont aussi principalement développés en interne par des équipes qui travaillent en étroite collaboration avec les équipes de la douane.
Le RFB applique aussi régulièrement les techniques d’exploration de données aux données hors ligne et est en train d’investir dans un vaste entrepôt de données afin de consolider tous les renseignements en lien tant avec le service des douanes qu’avec celui des recettes fiscales, ces derniers partageant du reste déjà le même environnement informatique. De cette manière, le RFB s’oriente vers un environnement de gestion des risques hautement technologique et intégré au niveau national, au sein duquel les trois systèmes présentés jouent un rôle important. Ce rôle ne manquera de devenir encore plus important si les systèmes des administrations des douanes dans le monde deviennent plus intégrés et connectés.
En savoir +
jorge.jambeiro@rfb.gov.br
gustavo.coutinho@rfb.gov.br
[1] Jambeiro Filho, Jorge. Artificial Intelligence in the Customs Selection System through Machine Learning (SISAM). Prêmio de Criatividade e Inovação da RFB, 2015 (Prix de créativité et de l’innovation du RFB 2015)
[2] Jambeiro Filho, Jorge; Jacques Wainer. HPB: A model for handling BN nodes with high cardinality parents. Journal of Machine Learning Research (JMLR), 9:2141–2170, 2008.