

Machine learning
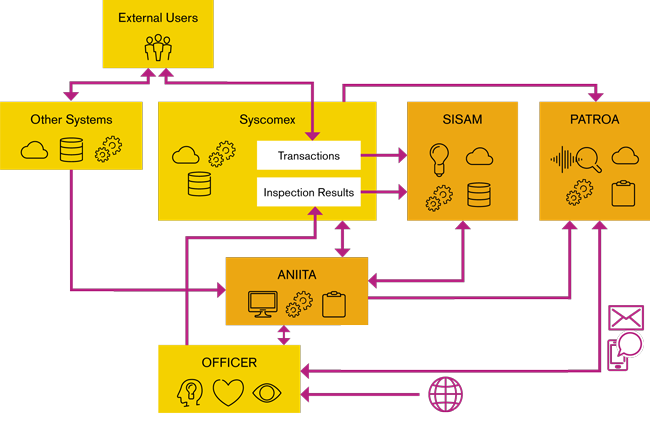
The artificial intelligence (AI) tool is called SISAM, a Portuguese acronym for “Customs Selection System through Machine Learning” in English. This computerized tool has been in use since August 2014 to evaluate the risk posed by importations. It runs 24/7 in one of the Brazilian government’s data centres. The AI tool “learns” from the history of import declarations, both through supervised and unsupervised learning – two ways in which machines (algorithms) can be set loose on a data set and expected to learn something useful from it.
With supervised learning, the expected output of the algorithm is already known and the algorithm is “taught” from a training data set that contains all the correct answers. For this “training,” import declarations that have been inspected by Customs officers are used to identify direct correlations between the presence or absence of errors and the patterns composed by the attributes of the declaration, such as:
Import declarations that were cleared without being inspected are used for unsupervised learning, and lead to the identification of typical patterns and atypical ones. The main example of this outlier detection process involves incompatibilities among the natural language description of goods and their declared nomenclature codes. Goods that are “unexpected” for a company with a certain economic activity code and goods that are bought from suppliers or manufacturers that do not usually sell the same goods to other Brazilian importers also call attention.
SISAM’s supervised and unsupervised learning capabilities are not actually separated. They both emerge from the same probabilistic models and share the same knowledge base, which contains data associated with 8.5 billion different patterns. For the data related to an individual product (item) of every registered import declaration, SISAM estimates the probability of about 30 types of errors.
These errors include false descriptions of goods, errors in the nomenclature codes, errors in the declared countries of origin, missing import licences, non-applicable tax regimes, wrong preferential tariff and “ex-tariff” claims (a scheme that enables Brazilian companies to reduce their tax burden when importing machinery, equipment or parts where domestic production is unable to replace them), and simply the use of wrong rates for the calculation of import duty, the tax on manufactured products, social contributions and anti-dumping duties.
For every attribute value that could be wrong on an item, SISAM estimates the probability of all alternative values, and evaluates the consequences of these values for taxes and administrative requirements. With this, SISAM calculates the return expectation of every possible inspection during the Customs clearance process. These expectations are later used to “feed” the decision and game theories, both of which support SISAM’s selection mechanism.
SISAM has the ability to explain, in “natural language” (the name used to refer to human language in the AI field), the reasons behind the selection of a cargo consignment, and provide details on how it calculated the risk probabilities. These explanations enable Customs officers to assess the system analysis and either ignore its recommendation or follow through on it. Although officers take the final decision to inspect or not, they benefit from the system’s capacity to find infractions that would certainly be lost among the thousands of import declarations.
In addition, SISAM’s knowledge base can be updated incrementally, allowing it to learn from new import declarations every day without being retrained. The learning process can also be distributed to several machines, and the resulting knowledge bases can all be added together later. SISAM’s knowledge base even allows information to be split from other information: for example, the evaluation of an importer’s behaviour against all information in the base except for information provided by the importer itself. In this way, SISAM avoids being induced by an importer to the conclusion that a certain behaviour is correct just because it is recurrent.
Moreover, SISAM has the resources to handle “mutant classes,” i.e. target classes whose definitions can change, which is atypical for supervised learning systems, but is necessary since the rules for the classification of goods are often changed. If, for example, one nomenclature code is split into two, for some time, data on the newly created codes will be scarce. SISAM can use the old and plentiful data to separate two new nomenclature codes from the other 10,000 codes in the nomenclature table, and use much less data to separate the two codes from each other, thereby achieving good performance faster.
When analysing any import declaration that has just been registered, SISAM considers the fact that behaviour patterns change with time. The system is also often required to analyse old import declarations, since they can be reviewed after Customs clearance. Any import declaration analysis is done with consideration being given to the tendencies that were prevalent on its exact registration date.
During the first presentations of SISAM to Customs officers, which took place when the system was still under development, they raised more resistance than excitement although the tests that were conducted had already proved its efficiency. But, the attitude of officers changed once they started receiving feedback from the system, explaining the reasoning behind its selection suggestions.
After being given suitable training, officers welcomed the system, and today their decision to check a transaction is based on SISAM’s suggestions 30% of the time. More detailed descriptions of the technical innovations that enabled SISAM’s development, including statistical results demonstrating the accuracy of its predictions and examples of the natural language explanations it generates, are available online [1 – 2].
Leveraging officers’ knowledge
Not all the knowledge of Brazilian Customs officers can be inferred automatically from Siscomex databases. Several other databases can affect officers’ decisions to various degrees of relevance. These professionals accumulate knowledge by seeing, touching and even smelling goods, as well as by mentally associating their observations to electronically available data. They also speak to importers, read detailed documentation and technical reports about goods, and search the internet regularly to obtain extra information.
However, as there is no way to directly access the human brain in order to guarantee that all this knowledge will be available when and where it is required, Brazil developed a system that tries to approach the idea. This software is called ANIITA, a Portuguese acronym for “Intelligent and Integrated Customs Transactions Analyzer” in English.
The development of ANIITA started in 2011 at the Uruguaiana border checkpoint. By that time, to assess the risk of an import declaration, Customs officers had to access at least seven different systems, including Siscomex. Each of these systems provided different data: for example, companies’ licences to trade internationally, their trade history, their internal revenue profile (containing measures such as gross income and number of employees), and information provided by foreign Customs administrations.
What ANIITA does is to extract data from multiple systems and show the most important information for the Customs clearance and risk assessment process on a single screen. It also offers user-friendly navigation from its central frame to detailed screens where all data usually necessary for clearance and risk assessment is available. This saves users a lot of time, as they do not have to manually browse many systems.
ANIITA can also process data and identify inconsistencies and known threats by crossing data from different databases and applying heuristic methods to the data. It also allows users to create rules based on their own knowledge of risks, and thus became an “expert system.” Officers can enter new rules according to the risk profiles of companies, people, goods, and a complex combination of attributes. ANIITA is a desktop application, but the database where the data and the rules to be applied are stored is centralized. This enables the data and rules to be shared across the organization, and an individual’s knowledge can be spread throughout the entire Customs risk management community.
Moreover, ANIITA makes use of the data available in the Indira system, which provides MERCOSUR countries with electronic access to data for all exports and imports among them, cross-checking the data from each foreign export declaration against the Brazilian import declaration. ANIITA is, therefore, able to find inconsistencies in the declarations: for example, it can find that the classification of goods declared at export does not match the classification of goods declared at import. Taking a step aside, this is a concrete example of how Brazil implemented the Globally Networked Customs (GNC) concept that was developed by the WCO.
ANIITA spread to almost all Customs units in Brazil by spontaneous adoption, and eventually became a corporate system, the use of which became mandatory for all officers with responsibility for deciding which goods need to be inspected. It was primarily designed to deal with import declarations, but, with its agile development structure, was soon expanded to handle express couriers, postal consignments, and export declarations. ANIITA now also offers different levels of privilege to users, allowing some of them to create rules that have to be nationally applied immediately.
Additional monitoring system
PATROA stands for “Real Time Customs Operations Monitoring System” and was launched in December 2017, completing the current Brazilian information technology (IT) ecosystem dedicated to Customs risk management. Just like ANIITA, it accepts human created rules, but instead of acting only under user demand, PATROA runs server side and applies the rules to transactions as soon as they are registered, thereby identifying risk profiles in real time.
In addition, PATROA can invoke ANIITA and SISAM to get their detailed analysis of a transaction, and then decide if an officer should be emailed or receive an instant message on his or her cell phone. The officer can respond and stop the transaction right away if convenient. PATROA can also decide not to call an officer immediately, but to start saving extra information about connected transactions, and produce a report that is only sent later to a human. These reports can, for example, describe non-complying behaviour from an authorized economic operator (AEO).
Conclusion
This article described three online Customs systems developed by the RFB, and how they interact and complement each other to provide a robust risk management solution for the country. All three are in constant evolution to gain precision and handle more types of transactions and infractions. They interface well with internal revenue intelligence systems, which are also mainly developed internally and whose development teams work closely with Customs teams.
The RFB also applies data mining techniques to offline data regularly, and is investing in a huge data lake solution to consolidate all information related to both the Customs and internal revenue services, two services that already share the same IT environment. In this way, the RFB is advancing toward a highly technological and integrated national risk management environment within which the three presented systems play an important role. They will be even more critical should the world-wide systems of Customs administrations become more integrated and connected.
More information
jorge.jambeiro@rfb.gov.br
gustavo.coutinho@rfb.gov.br
[1] Jambeiro Filho, Jorge. Artificial Intelligence in the Customs Selection System through Machine Learning (SISAM). Prêmio de Criatividade e Inovação da RFB, 2015.
[2] Jambeiro Filho, Jorge; Jacques Wainer. HPB: A model for handling BN nodes with high cardinality parents. Journal of Machine Learning Research (JMLR), 9:2141–2170, 2008.