

Examples
The following example shows an import transaction analysis using one-dimensional data:
Transaction: Consignment X is sent to importer Y by shipper Z with a value of $m and a weight of N.
Assessment model:
Adopting one-dimensional analytical techniques such as these severely limits the ability of Customs administrations to adapt selectivity rules for changing market, regulatory, trade or company conditions.
Negative impact
The results of survey activities conducted among dozens of Customs administrations by my company, Publican Trade Solutions, show that 94% of the participants reported significant limitations in their ability to achieve stable predictive analytical models for fraud detection. Meanwhile, 84% reported full reliance on static rule-based risk engines to drive decision-making, with these rules fed largely by one-time tips, specific regulatory changes or historical models.
On average, the surveyed administrations reported that physical inspection was conducted on 34% of all shipments, with only a 2.1% hit rate.
Static rules are proving ineffective at detecting dynamic fraud and are a leading cause of time-consuming inspection cycles and revenue leakage.
Predictive analysis with digital vetting (multi-dimensional data and AI modelling)
To remedy the situation, Customs should use dynamic data that leverage artificial intelligence to model every possible scenario. Such models are designed for a world where each transaction is different and cannot be assessed according to historical patterns. These scenarios consider existing models based on historical and domestic data, alongside rapidly constructed models based on up-to-date data which reflect real-time market, regulatory and trade conditions. In this sense, they are “multi-dimensional” and “predictive”.
The following example shows an import transaction analysis using multi-dimensional data:
Transaction: Consignment X is sent to importer Y by shipper Z with a value of $m and a weight of N.
Assessment model:
Such a model leverages multiple inter-dependent data sets, which also consider data on real-time and current conditions.
This methodology is known as “Digital Vetting”, which reflects the fact that assessment models harness all the data available at any given time to vet shipments for fraud – a direct outcome of global digitalization.
Private-sector technology for Digital Vetting
The fact remains that introducing multi-disciplinary, unstructured, varied and highly unstable data from diversified and dispersed sources within an analytical system is difficult. One solution is to use the technologies, platforms and services of private-sector organizations specializing in the construction and implementation of AI models to create deviation indicators and detect patterns indicative of fraud.
Such models are developed by retrieving global data from trade, economic, open and commercial datasets. Once the data are collected and analysed, computational modelling based on artificial intelligence is used to develop and apply globally relevant datasets in order to identify patterns. Data on trade operator relationships and structures, as well as item prices and valuations, are of special importance for Customs.
Because they change over time and location, the data need to be constantly analysed for variances, and fraud indicators need to be adjusted accordingly. Furthermore, scenarios must also be extrapolated from existing data on a continual basis with variances and patterns determined by dynamic inputs from myriad global and localized sources.
The analytical system which is then developed can also ingest data on domestic entities and historical transactions. Once these data are introduced into the AI model, the following elements can be created:
Models can be quickly trained to identify designated threat vectors, relevant only to specific countries or regions. This process covers restricted and prohibited items, as well tariff-specific selectivity parameters. National inputs regarding reference pricing and valuation models should also be integrated. For example, country-specific depreciation models for used vehicles, or highly specific commodities, are considered by the analytical models.
Real-world scenarios
The following example shows the assessment of a shipment of office furniture. Key analytical actions include:

For the assessment of consignments of used vehicles, it is important to be able to determine the model, value and true condition of the car. Key analytical actions include determining the correlation between the declared vehicle identification number (VIN) and the image of the car, the provided documentation, and the declared mileage. An analysis is also carried out digitally to assess any damage or anomalies, the pricing and valuation of the vehicle and the accuracy of the declared title status.

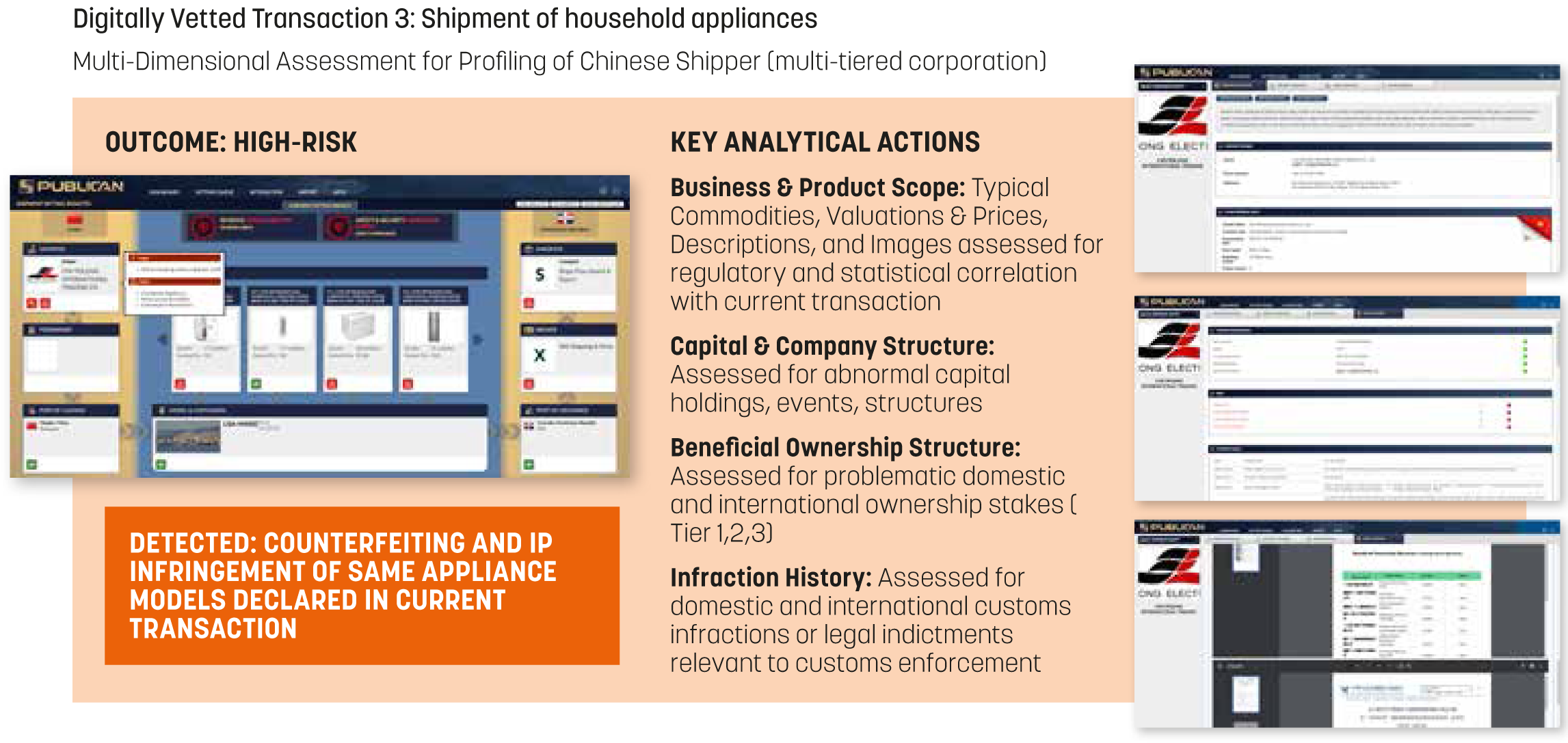
For common goods such as household appliances which are highly prone to fraud and require resource intensive inspections, key digital analytical actions include:
Cooperating to build data ecosystems
Analytical tools leveraging multi-dimensional data are fast becoming an integral and irreplaceable component of the Customs data ecosystem. As more global and local data come into play, AI models can be sharpened, and the scenarios developed will become deeper and more accurate.
As the Data Revolution continues to unfold, Customs administrations can solve many challenges by using appropriate technology. Valuing and inspecting cross-border e‑commerce shipments can be facilitated, the release of critical goods accelerated, audit structures designed to be more flexible, origin attribution verified, and AEO application and monitoring made easy.
Bearing all that in mind, there is fertile ground for public/private-sector cooperation. By mutually leveraging their respective capabilities and capital in operational, regulatory, and technological realms, the public and private sectors can create a reliable and high-performing data ecosystem.
More information
david.smason@publican.global
www.publican.global