
Paper on the use of container status messages wins ‘best paper’ award
16 March 2016
The WCO recognized the value of research and education as part of the response to the many challenges Customs administrations are facing. Crucial in stimulating research is enabling researchers and professionals to interact with each other. As hosts of the 5th TI Forum, the Customs administration of the Netherlands promoted further interaction between the research and development (R&D) and Customs communities by integrating a special track devoted to the latest research and developments in the field of technology use by Customs administrations. An award was given to the best research paper presented during the Forum.
The TI Forum research track was hosted by the Rotterdam School of Management (RSM) and Fontys University of Applied Sciences, and was supported by the European Commission’s (EC’s) Customs Detection Technology Expert Group (CDTG). Following a call for papers and posters for the special track, 22 submissions were received from all over the world. A programme committee, chaired by Professor Tan from the RSM, refereed the papers and posters, and selected the best paper. Accepted papers were presented at the T&I Forum in a break-out session, while the posters were put on display throughout the event. The winning paper, on the use of container status messages for improved targeting, by Aris Tsois et al., was also presented as a plenary lecture in the Forum’s closing session.
A container status message (CSM) describes an event that has occurred in relation to a container. These relatively well standardized messages are exchanged by companies involved in the transport of a container, and comprise information on the whereabouts of a container and its contents. Events recorded in a CSM include the stuffing of a container, the loading of a container on a vessel, and the discharge of a container from a vessel. The data captured in a CSM consists of the container number, a description of the event, the location at which the event took place, the dates and times of the event, the identification of an associated vessel, the load status of the container, and the name of the carrier company.
Apart from its use among commercial supply chain actors, CSM’s are also used by Customs and border management authorities, enabling them to trace back the handling actions pertaining to a specific container. Customs and Border Protection in the United States, for example, requires CSM’s as part of its Importer Security Filing and Additional Carrier Requirements rule (commonly known as ‘10+2’). Even though standardized, as with any real-time data the CSM is not necessarily uniform, nor is it complete, chronological in arrival, or lacking in mistakes. Further, in a fast moving world vessels are often transferred from one owner to another, and the tendency to come up with names of ships that are not unique is remarkable. This all calls for dedicated treatment of the CSM data before it can be used for intelligence purposes by law enforcement agencies.
In fact, this dedicated treatment of CSM data was actually the first step of the research work that Aris Tsois and his group undertook at the EC’s Joint Research Centre (JRC). In extracting useful information from the CSM’s, Tsois et al. intend to answer the following questions representing the five relevant phases in a container’s journey:
- Pre-loading – when and where do the goods get stuffed in the container?
- First loading – when and where do the goods start their deep-sea maritime transport?
- Transhipment – when and where was the container transhipped while carrying the goods?
- Final discharge – when and where do the good end their deep-sea maritime transport?
- Final destination – when and where do the goods get de-stuffed from the container?
They did so by devising container-trip information (CTI) for every journey of a single container from origin to final destination using a machine learning algorithm. In setting-up the CTI, CSM information is assigned to the five phases mentioned above using a conditional random fields algorithm. The data calculated from the CSM’s contains important information: the container identifier; the location involved; and the time period covered in the phase of the journey and the vessel involved, for every phase. In cases where the algorithm signals the absence of relevant CSM data, it will infer from the data that is present the most likely value for the missing data.
Some questions, however, could not be directly answered from the CSM information. For example, no CSM is generated when a container stays on board a vessel while it calls at one or more ports on the way to its final destination, and as a consequence no CTI entry is made on the stay at these in-between ports both in terms of location and duration. Customs administrations on the other hand have found information on the location of an in-between stop and the duration of that stop to be of relevance in applying their risk assessment procedures.
For this reason, the JRC team also developed vessel-stop information (VSI) alongside CTI. Using a specifically designed vessel stop inference algorithm and employing all available CSM information, the build-up of the needed information became possible. As it turns out, this ‘big data’ analytic approach to CSM’s yielded information which describes the location and the duration of in-between vessel stops in sufficient detail. Of course some challenges remain with this approach as the names of vessels may be the same, precision in date and time reporting is far from ideal, and data may be altogether erroneous. Two assumptions were made in order to confront these challenges: separate events at the same time with two vessels with the same name refer to one single vessel; and two vessels undergoing the same events at the same time refer to the same vessel.
The newly developed CTI and VSI lay the ground for innovative analysis of CSM data for profiling and container targeting purposes by Customs and border management authorities. Where officers involved in targeting currently attempt to trace back the journey of a single container, the developments described in Tsois’s paper will enable an algorithmic evaluation of a large number of containers at one time – all the containers on a vessel arriving at the port of Rotterdam, for example. The key actually is to combine VSI’s and CTI’s present on the vessel as a whole. CSM’s on a single container can leave one guessing. But aggregated sets of CTI’s and VSI’s allow for the filling of voids and the correcting of errors in CSM’s, and the defining of pre-loading, first loading, transhipment, final discharge and final destination of every container. Moreover, these sets of data allow one to generate supplementary information on transhipment stops that the vessel passed through.
ConTraffic: improving route information to enhance risk management
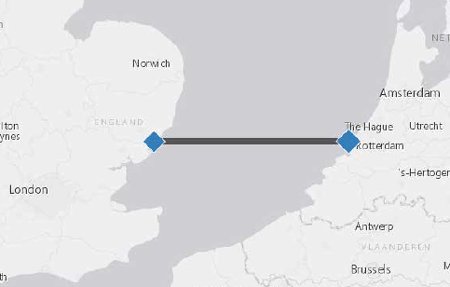
To enable law enforcement agencies to actually use these findings in everyday practise, a visual analytics tool and the ability to include risk indicators had to be constructed. The developed prototype of the visual analytics tool has now been included in the EC’s CONTRAFFIC website, which provides information on container routes as well as risk assessment services to users from Customs and security authorities. The website enables registered users to construct geographical maps, timelines and
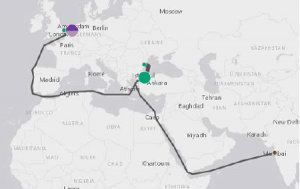
text tables from the billions of CSM’s and the millions of CTI’s and VSI’s calculated from them. This highly insightful way of presenting dense information can be used to select those container trips that are subject to route-based indications for wrongly declared origin, abnormal handling time, suspect ports en route, and the smuggling of drugs and weapons. In his paper, Tsois actually gives examples of a number of algorithms that could produce insightful indicators to this end.
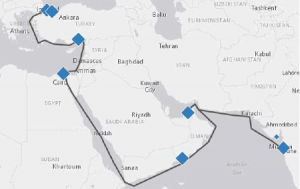
Tsois and his team have, over the course of their research and development work on CSM’s, gathered a large community of Customs experts that are kept up-to-date on the latest results – for example, through workshops. It is likely that this community will grow even larger following the presentation of his paper at the T&I Forum. The paper is a rare demonstration of a broadly applicable development, based on widely available source material that has been developed to be practical and, moreover, made available to the actual end-users themselves.
More information
m.slegt@belastingdienst.nl
www.douane.nl