
At the time of writing, there are 164 countries that are members of the WTO; the most recent addition being Afghanistan in July 2016. In addition, several other countries have chosen voluntarily to adopt the Agreement as the basis for determining Customs value. To meet the terms of their international obligations, Customs officers generally apply up to six practical methods to determine the value of goods.
It is understood that the two most effective methods of valuation relate to comparing the shipment in question (if the transaction value is in dispute) to the transaction value of identical or similar goods entering the same economy. Construction of a valuation database has been the traditional way to ascertain a declared item’s likely valuation as compared to the average declared value of identical or similar goods.
There are numerous administrative and technical complexities with respect to administering and applying a valuation database. Among other things, this requires:
Each of these practices has its own challenges. Customs valuation experts, for example, are rare, and updating a database is a resource-intensive process. Asking brokers to apply tariff specific codes is challenging, even if only across a small section of the tariff where valuation concerns are perceived to be the most acute. As price reference data is usually based on the country of import, one must find data that is relevant for its country (USA based price reference data will be of limited use elsewhere in the world).
Moreover, if the goods are misclassified, incorrect pricing reference data from a valuation database may be applied to the item in question. Experts in valuation may not be experts in commodity classification, although the common problems of undervaluation and misclassification are somewhat interwoven. It’s hard to tackle one in isolation to the other.
Machine learning
Machine learning, i.e. the process of teaching a computer system how to make accurate predictions when fed data, can be of tremendous help here. It is, however, an area where we believe Customs administrations do not have enough information, and we would like in the following paragraphs to explain in more detail how machines, or in other words computers, incorporating a predictive modelling tool, can do it.
Today, predictive models can determine a goods tariff classification and value based on the inputs listed in Table 1. The models still work, even if some of the information is not provided, but they are most accurate when they are given as much information as possible.
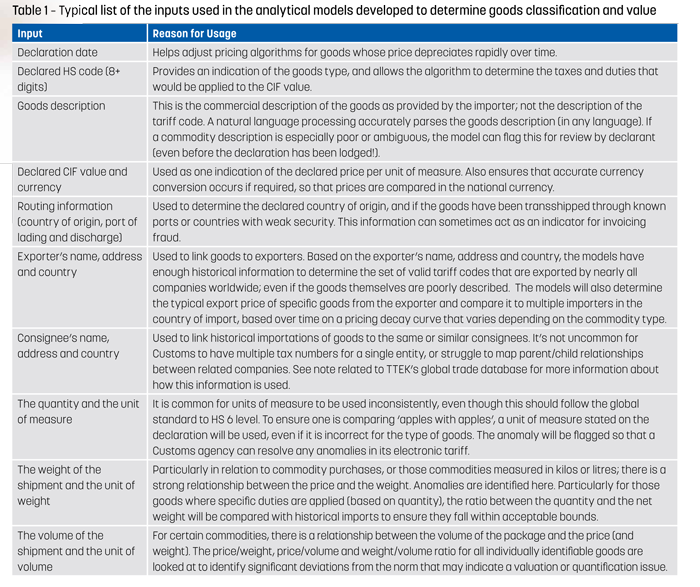
As you can see in Table 1, the analytical models we are referring to take a lot more into consideration than simply a comparison of the declared value and the country of origin to determine an estimated true CIF value. Models can be trained in several languages and the algorithms used take so many discrete factors into account that they easily surpass the analytical capacities of the best valuation database or valuation expert when applied at scale.
Clusters of acceptable values for identical/comparable goods and the outlying values for goods that fall outside the acceptable range can be identified, and the results rendered in the form of an interactive graph or cluster diagram; such that a Customs inspector can easily visualize the analysis to determine any subsequent course of action.
What to look for in the goods description
There are a number of indicators that the models look at in a commodity description to help identify what the goods are, and any anomalies or attempts at obfuscation:
The machine learning model looks at all the phrases and words in the goods description, and uses them to add or subtract an amount from the base cost based on previous importations of a similar good. What’s more, the models work across multiple languages, i.e. words, phrases or patterns in Spanish or Chinese can be compared against their English equivalents. A goods description containing two languages can be parsed as effectively as a description in just one language. The same multi-language matching occurs when referencing exporter, importers and consignee names. i.e. ‘Honda Motor Co’ will match with “本田技研工業.”
The result
So, once a computer system has performed an analysis based on these models, what happens next?
Misclassification – The system will indicate a probability for each declared item, i.e. a number between zero and one, that the declared HS code is correct. It will also provide a list of up to five different HS codes that could apply to the goods concerned, with a probability measure. In other words, the officer looking at the information can make an accurate determination as to whether the declared code is correct or not, and, if not, what it should be. This is all well and good, but obviously Customs is most interested in cases of misclassification where the tax and duty rates that apply to the declared HS codes are different to the ones that apply to the code deemed more probable or correct. The system also automatically calculates the new taxes and duties that would apply if this code was used, so that Customs can quickly determine if it is financially cost effective to build a misclassification case against the importer.
Undervaluation – The system will also predict the CIF value of each declared item based on the information provided, including on the history of previous importations of such goods types. More recent transactions are more heavily weighted for those goods types where the price decay curve is steep, such as for products that quickly lose value through obsolescence, such as a recent mobile phone model. The system will also recalculate the duties and taxes payable, based on this “new” value. Optionally, the system can question both the declared CIF value and the declared HS code if it believes that both a case of undervaluation and misclassification have occurred.
Incorrect country of origin – As a byproduct, the system can accurately determine if the stated country of origin is likely to be correct or not, based on the country’s history of importations of such types of goods. If the country of origin is considered unusual, the system will list the top five most likely countries of origin, with a probability of each one being correct. Traders may disguise the country of origin to take advantage of preferential duties or free trade agreements. It’s another factor in valuation control.
So, for any transaction, the system can identify if the goods are likely to have been misclassified and/or undervalued, and/or if their origin has been misstated. The estimated revenue foregone is also calculated so that Customs can make a quick judgement as to whether it is worth expending the effort to build a case against an importer.
It gets better…
The system can also quickly determine the amount of security (bond/guarantee) that a trader should pay to Customs before they release the goods, should such a procedure be provided for in the Customs Code. Let’s remember that this procedure is enshrined in the WCO Revised Kyoto Convention on the simplification and harmonization of Customs procedures in Section 3.43 (Clearance and other Customs Formalities):
“When an offence has been detected, the Customs shall not wait for the completion of administrative or legal action before they release the goods, provided that the goods are not liable to confiscation or forfeiture or to be needed as evidence at some later stage and that the declarant pays the duties and taxes and furnishes security to ensure collection of any additional duties and taxes and of any penalties which may be imposed.”
Accordingly, even if a revenue evasion offence may have been committed, the goods should be released if they are otherwise admissible, and administrative action shall be taken later to collect duties and taxes owed. However, in many countries, this procedure cannot be actioned as it takes Customs a long time to determine the amount of security that should be lodged before release pending a thorough investigation. Consequently, the valuation case is often finalized before the declaration is released; potentially taking a few days. This holds up the supply chain, including other goods that were part of the same shipment if a partial release is not supported by the administration.
Identifying honest mistakes
It is common for traders or brokers to make mistakes when entering values, weights and measures on a Customs declaration. Analytical models can identify that a declaration has been populated with incorrect information and/or an ambiguous or misleading goods description as well as flag the declaration for document review and possible amendment, listing the item(s) in question and the content that it believes have been mistyped.
At scale
It is a common scenario where a Customs post-clearance audit (PCA) team are somewhat understaffed, under-resourced, and without the analytical tools necessary to do their job. The machine learning models we are referring to in this article can be run against the last 2-3 years of Customs declaration data to determine those traders who are potentially the largest culprits with respect to undervaluation and misclassification, enabling the PCA team to work at their most efficient. They can target those traders and commodity types that will bring in the most amount of additional revenue to the treasury if prosecuted. This would also have a deterrent effect. The payback on such an initiative can be measured in days or weeks.
Accuracy
Users of the analytical tools mentioned here report an accuracy rate of about 85%, which is improving all the time. If the results are not conclusive and raise uncertainties, the system will say so and Customs will then either discard the results or request the importers to provide less ambiguous information as uncertainty is generally indicative of a likely data quality issue with the underlying declaration.
Transfer pricing and the related parties test
Evidence suggests that cross-border transactions between related parties contribute to approximately 30% of global trade. As per OECD Guidelines, a transaction between related parties should comply with the “Arm’s Length Principle”: the conditions (prices, profit margins, etc.) in transactions between related parties should be the same as those that would have prevailed between two independent parties in a similar transaction under similar conditions.
Identifying the ultimate exporter and consignee of the goods is generally quite easy, as it should be listed on the goods declaration. However, Customs needs to evaluate all the different ways that a related exporter and importer could be described, in order to develop a related-parties map.
As an example, here’s a list of some parties related to Honda Corp. in Malaysia:
And in South Korea:
Clearly, if the exporter and the importer both contain the name Honda, then a related party transaction is identifiable using language processing at the data level; but what if the transaction were between ‘UMW Industrial Power’ in Malaysia and ‘SDN Company Ltd’ in Korea? How can you identify if this is a related party transaction?
The Trade Data Network
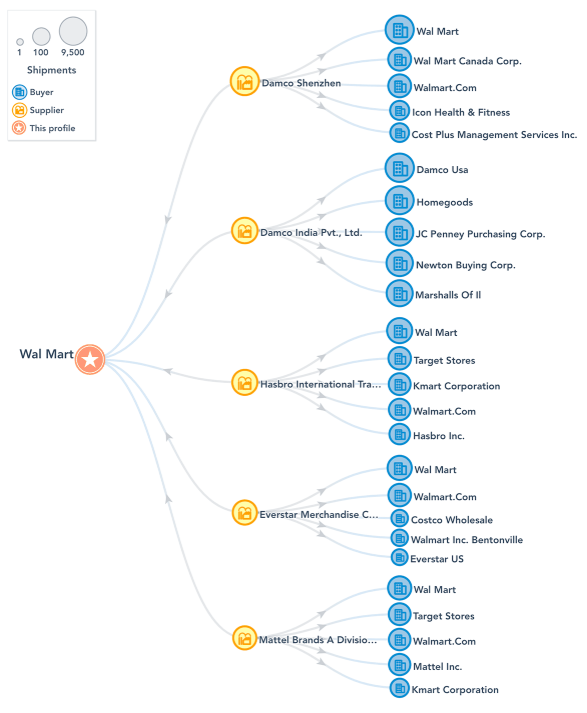
Data is available on nearly 50% of the shipments transported across borders with the name of the companies involved in the transaction at export and import, as well as the list of their directors and shareholders obtained by creating a global company registration database. Acquiring such data was the first step, but exploiting the data required cleaning, connecting, and harmonizing datasets describing the transactions and travel networks. Parent-child relationships between related entities also had to be mapped. Public and commercially available data was then joined to create a reference set on global networks and flows that we called the Trade Data Network.
When the pertinent data encapsulated within a Customs declaration is overlaid on top of this data network, transactions from related parties that are disguised as non-related exporters and importers appear. The Trade Data Network can identify shelf companies that may have been established to complete only a few shipments before being shut down, by looking at the name of their directors or at the modus operandi of the transaction. For example, the exporter just started trading in a commodity with a new country, and the importer ordered a quantity of goods that seems odd. Although the Trade Data Network is a rather new product, users are already obtaining encouraging results with respect to the mapping of transnational crime organizations.
Added value
There are software applications on the market that fuse related data to provide a centralized, aggregated view of information from disparate sources, integrate with existing systems, and uncover connections and patterns in order to obtain intelligence. IBM I2 Analyze or Palantir are some of the environments developed to this end.
However, in order to use the tools listed above, Customs administrations must have suitable sources of reference and transactional data, or actionable intelligence to link data together and identify patterns, or the resources to transform the data that they do collect into a form that can be intelligently analysed by such systems. Even then, Customs may only have access to their own data and perhaps that of their neighbours; they don’t generally have visibility of the full global trading landscape. Of course, Customs can pay a third-party to assist in this process of information capture, transformation and analysis, but it is expensive, error-prone, and time consuming. This approach can work effectively for States that have the necessary funds and resources to build large data lakes and contract in the expertise to build models linking datasets together, and train highly skilled analysts to navigate their way through this knowledge tree to identify insights.
The Trade Data Network is different in that it already contains a massive corpus of valuable worldwide intelligence that would be immensely challenging for one country to compile. By mapping a country’s Customs data on top of well understood trade flows, Customs analysts can rapidly identify actionable anomalies in a shipment without requiring a copious amount of additional intelligence gathering and input into the system.
It is not just a product, it’s an intelligence system that comes pre-loaded with statistically normal (and ab-normal) transactions. By comparing incoming transactions against what is normal, analysts can identify the few transactions that are abnormal. When automatically overlaying a new shipment on top of existing trading relationship networks like that shown below, we can identify related party transactions, or transactions between new parties; or just transactions that don’t make logical sense. By automatically triaging the thousands of Customs declarations that a small to medium-sized country will receive in a typical day, the Trade Data Network analysis helps identify those small number of transactions that are truly anomalous.
Advances in cloud computation, natural language processing, and machine learning now make it affordable to put this actionable intelligence in the hands of small and medium GDP nations, at a price that they can afford.
Learning from others
The WTO Valuation Agreement states that values should be compared with historical/comparable imports into the same country. Early evidence suggests that it may be possible to train a model based on data from one country, and apply the findings to a similar country in the region. This means that as more Customs administrations adopt this modern approach to the practical problem of valuation control, they have the potential to strengthen each other’s ability to detect revenue leakage; not by sharing declaration information across borders, but by sharing some of the calculations and thresholds inherent in valuation models. Examples of clusters of nations where the data suggests that they may mutually benefit from each other’s insights include:
Next steps
Once it has been proven that an exporter or importer is not compliant, it is easy to map the trading relationships of the companies or persons of interest concerned, and to identify other potential fraud cases or other parties that may also be involved in systemic fraud or other illegal activities. We are currently working on the next-generation revenue leakage model that will facilitate this process.
We are also looking at how to combine valuation controls with scanned image detection algorithms to determine if the relative volumes of the commodities declared approximate that shown in the scanned image. We are currently looking for partners involved in supplying technology for non-intrusive inspections to work with us on the next generation of machine learning models incorporating the analysis of scanned images and comparing them to the information on the underlying declaration and bill of lading.
Deployment
We understand the sensitivities around Customs data, and that many countries have strict policies related to data sovereignty and data sharing. Fortunately, we can deploy our technology using application containers inside a Customs data centre, in the cloud, or as a hybrid solution where all misclassification and valuation models run on-premises, but small anonymized and codified consignee information is sent to our Trade Data Network using a secure encrypted connection to our private cloud service.
In addition, we can work with any Customs data, and can receive transaction data for analysis either via an application programming interface, or a direct read of the underlying database tables. Historical data provided by a Customs administration in csv or similar format can also be processed effectively.
Do not hesitate to contact us should you require any further information. We will be exhibiting at the WCO AEO Conference in Dubai and at the next WCO IT Conference in Indonesia, so stop by our stand to discuss your needs and the solutions we have developed.
More information
www.ttekglobal.com