

Comment la Douane indienne exploite l’analyse des données aux fins d’une gestion des risques efficace
Par M. Ramesh et Sruti Vijayakumar, Centre national de ciblage douanier, Direction centrale des impôts indirects et des douanes (CBIC), Inde
Les méthodes de base pour la sélection du fret à des fins d’inspection et de vérification comportent leurs limites. Pour améliorer leur capacité de lutte contre la fraude, les administrations des douanes ont besoin de changer radicalement de paradigme en matière de ciblage. Elles doivent tirer parti des possibilités qu’offre la science des données, un domaine académique interdisciplinaire qui se fonde sur les statistiques, l’informatique scientifique, ainsi que sur les méthodes, processus, algorithmes et systèmes scientifiques pour extraire ou extrapoler des informations et des constatations à partir de données bruitées[1], structurées ou non. Pour pouvoir exploiter les outils de la science des données, il faut toutefois compter sur une architecture de données solide. Le présent article propose un tour d’horizon de l’architecture de pointe mise au point par la Douane indienne.
L’architecture d’analyse des données renvoie à la conception de différents systèmes de données au sein d’une organisation et aux règles qui régissent la manière dont les données sont recueillies et entreposées. Elle représente la base des opérations de traitement des données et des applications d’intelligence artificielle (IA). La Douane indienne a mis au point une architecture d’analyse automatique des données qui comprend cinq couches interdépendantes, chacune contribuant à une approche globale et dynamique du ciblage et de la détection. Dans le présent article, nous mettrons en évidence les capacités de l’architecture en matière d’analyse des mégadonnées (big data) aux fins d’un ciblage précis.
La robustesse de l’architecture est sous-tendue par sa capacité à combiner de multiples composants de pointe de la science des données avec l’intelligence humaine. Elle permet à la Douane indienne d’intégrer de multiples sources de données, de générer des constatations pertinentes et d’utiliser des cibles définies à la fois par la science des données et par l’expertise humaine. Une boucle de rétroaction itérative permet d’adapter les stratégies de détection, ce qui rend le modèle résilient face à l’évolution des techniques de contrebande. Ces différents éléments sont expliqués ci-après.
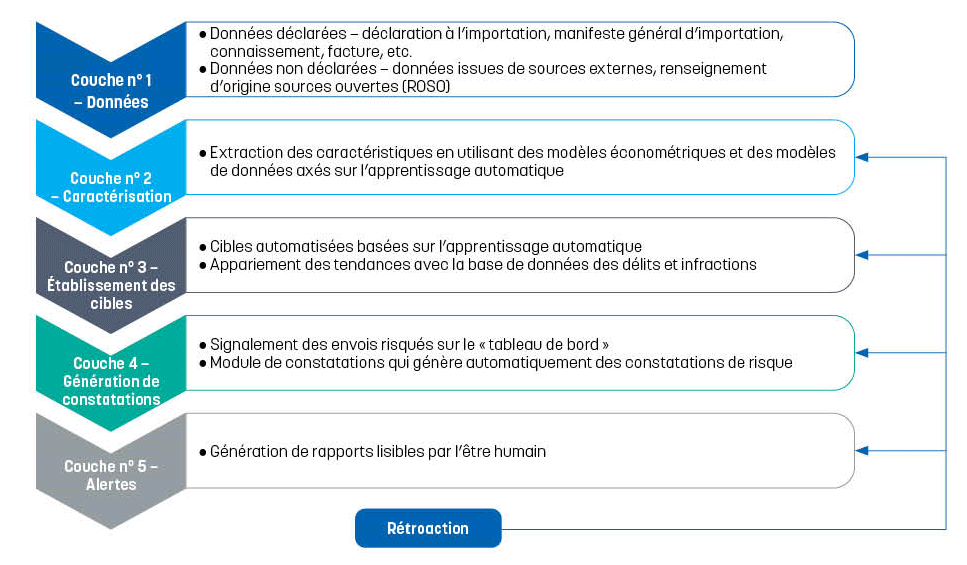
Couche n° 1 : Données déclarées et non déclarées
La première couche implique la collecte, le collationnement (l’assemblage des informations écrites suivant un ordre ou une séquence standard) et la validation croisée des données disponibles au moment de l’importation des marchandises. Ce processus couvre tant les données déclarées que non déclarées.
Les données déclarées, qui constituent les points de données initiaux, comprennent, entre autres, les données soumises dans la déclaration d’importation et dans le manifeste général d’importation ainsi que les données reprises sur la facture, le connaissement et les licences. Si les documents fournis par les importateurs et les transporteurs sont sur support papier ou en format PDF, les données ne peuvent pas être directement utilisées pour une analyse automatique des risques et il faut dès lors pouvoir compter sur des outils de reconnaissance optique de caractères (OCR) pour pouvoir créer des solutions automatisées qui transforment les données disponibles en format lisible par ordinateur.
Les données dites « non déclarées » désignent celles qui sont obtenues à travers les renseignements d’origine sources ouvertes (ROSO) et les répertoires de données faisant l’objet d’une propriété exclusive. Ces renseignements et répertoires constituent des sources complémentaires d’informations qui permettent d’affiner l’analyse. Ils incluent aussi des données tirées des images de scanographie émanant des appareils d’inspection non intrusive. Il est possible de remonter vers les systèmes sources des données à travers une piste de vérification.
Le but de cette première couche est de collationner les données primaires recueillies à la source relatives à une déclaration d’importation spécifique. La fourchette de données collectées dépasse de loin l’opération d’importation à l’examen et englobe des renseignements concernant de nombreuses autres importations comparables. Ce jeu de données collectives sert à alimenter les algorithmes ou les modèles qui sont hébergés dans les couches suivantes, notamment celles relatives à l’analyse d’images, au classement automatisé, et aux modèles générant des constatations sur la base des résultats obtenus. À travers les informations puisées dans cette couche, ces algorithmes et modèles peuvent dégager des tendances uniques ou des anomalies portant spécifiquement sur l’opération d’importation à l’examen.
Couche n° 2 : Caractérisation
Les données brutes ne servent pas à « entraîner » les algorithmes d’apprentissage automatique. À la place, les scientifiques des données consacrent beaucoup de temps à la caractérisation (ou ingénierie des caractéristiques). Ce processus consiste à transformer les données brutes en caractéristiques (aussi appelées variables ou attributs) qui sont utilisables par les modèles d’apprentissage automatique. Il est indispensable pour cela de bien comprendre les données d’apprentissage et les problèmes ciblés. La caractérisation n’est pas exclusivement manuelle. En effet, elle est effectuée via des algorithmes qui analysent et regroupent les jeux de données non étiquetées sans intervention humaine (par le biais de l’apprentissage automatique non supervisé), ainsi que moyennant des techniques d’augmentation des caractéristiques et des modèles économétriques.
La couche n° 2 se compose de nombreux « thèmes » qui sont présents dans chaque transaction d’importation, comme par exemple, l’importateur, le fournisseur, le pays d’origine et le pays d’expédition. Après un examen exhaustif et sur la base d’une compréhension détaillée des données combinées sous la couche n° 1, de multiples « caractéristiques » sont créées pour chacun de ces thèmes. Ainsi, la couche n° 2 se compose de nombreux thèmes et des caractéristiques leur correspondant qui sont autant de constatations tirées des données brutes.
Le principal objectif de cette seconde couche est d’incorporer un vaste éventail d’aspects liés au commerce qui sont directement ou indirectement reflétés dans les données. Par exemple, le thème « importateur » pourrait inclure des caractéristiques telles que la fréquence des importations, les marchandises importées ou le type d’importateur. Certains attributs, tels que les informations géo-démographiques sur l’importateur, sont pris en compte pour l’élaboration de possibles considérations en lien avec le risque concernant les pratiques d’importation de l’importateur en cause.
Les caractéristiques peuvent être créées en utilisant l’apprentissage automatique non supervisé. Ces outils permettent de codifier des informations détaillées sur les fournisseurs et la description précise des marchandises par article ce qui est essentiel aux fins d’un ciblage ultérieur.
Couche n° 3 : Établissement des cibles
Les activités de contrebande se cachent souvent derrière des pratiques commerciales bien établies, mais il est possible de constater des déviations subtiles à un ou à plusieurs points de données. Conçue de manière robuste, la couche n° 3 permet de détecter les déclarations d’importation suspectes à travers des « cibles » soigneusement créées pour repérer ces déviations ou anomalies. Les cibles sont créées tant par ordinateur que par l’être humain, à travers l’analyse des tendances en matière de contrebande, des saisies passées et des menaces émergentes. Elles sont associées à des algorithmes qui sont ensuite encodés dans l’ordinateur en utilisant les caractéristiques de la couche n° 2.
Par exemple, les cibles générées par ordinateur signalent les cas de classement incorrect et de sous-évaluation. L’appariement des tendances avec la base de données des délits et infractions dans le système permet un ciblage automatique. La couche n° 3 représente donc une étape déterminante où diverses cibles sont créées pour automatiquement identifier différents types de risques. Un jeu complet et exhaustif de cibles garantit la solidité du modèle.
Couche n° 4 : Couche décisionnelle – génération de constatations
La couche n° 4 combine les constatations de risque générées par ordinateur et les cibles en vue de déterminer, avec précision, quels sont les envois importés qui peuvent présenter un risque. Elle crée un « tableau de bord » en conséquence. Construit sur la base des cibles définies par la couche précédente, ce tableau de bord constitue un modèle décisionnel mis sur pied grâce à l’apprentissage automatique et qui met en évidence les envois risqués.
Les constatations de risques sont le résultat de l’analyse du jeu de données de la couche n° 1 combinée au traitement des données sous les couches n° 2 et n° 3. Elles sont générées automatiquement par ordinateur au regard de chaque déclaration d’importation. Elles mettent en lumière les facteurs de risque potentiel, comme les changements fréquents et soudains de l’importateur au niveau des ports choisis, des marchandises, des fournisseurs, des agents en douane, ou encore la corrélation entre l’importateur et le fournisseur, et l’analyse des risques associés aux fournisseurs. En fonction des résultats de l’analyse menée sous cette couche, la décision est prise de retenir ou non les marchandises. Les résultats vont alors alimenter la couche n° 5.
Couche n° 5 : Génération d’alertes
La dernière couche distille l’analyse, les constatations et les conclusions, et les résultats pour formuler des rapports lisibles par l’être humain et faciles à comprendre. Les douaniers ont alors accès à une vision d’ensemble des anomalies et des tendances détectées, et peuvent donc prendre une décision et adopter des mesures rapidement. La lisibilité des rapports générés par le système est cruciale : un rapport bien conçu et facile à lire permet de créer un pont entre les constatations analytiques obtenues via l’architecture et les douaniers déployés aux ports, qui dépendent de ces informations pour prendre les mesures qui s’imposent.
La boucle de rétroaction dynamique : affiner les stratégies de ciblage
Cette architecture offre spécifiquement la possibilité de réagir de manière dynamique à travers l’incorporation d’une boucle de rétroaction itérative. Le processus permet de garantir que le modèle analytique puisse évoluer en continu et être adapté aux nouvelles tendances en matière de contrebande. Les données relatives aux déclarations d’importation qui sont étiquetées comme « délits » et entreposées dans la base de données sur les délits et infractions sont réutilisées dans les couches n° 2, 3, 4 et 5. Tous les délits sont inclus dans la base de données, qu’ils aient été relevés via le modèle de ciblage ou par une autre méthode.
Au niveau de la couche n° 2, par exemple, tant les détections avérées de contrebande que les « faux résultats positifs » sont des sources d’informations extrêmement utiles. La rétroaction sert à réévaluer la gamme des caractéristiques incorporées à l’analyse, dans le but d’en introduire éventuellement de nouvelles qui se sont avérées efficaces pour la détection effective de pratiques commerciales illégales. Ce processus contribue à son tour à revoir les cibles définies par les experts sous la couche n° 3, à affiner encore la prise de décisions sous la couche n° 4 et à améliorer la précision des rapports et leur lisibilité par l’être humain sous la couche n° 5.
Performance
Cette architecture de science des données, qui allie l’analyse des données à l’intelligence humaine, s’est révélée efficace et performante pour la détection des cas de contrebande de marchandises ainsi que d’articles soumis à des restrictions et à des interdictions à travers la frontière. Grâce à ce modèle, par exemple, quelque 3 000 kilos d’héroïne passés en contrebande depuis l’Afghanistan ont été retrouvés dans un envoi importé par voie maritime au port de Mundra, dans le Gujarat. Parmi les autres cas détectés, citons les 7,2 millions de cigarettes de marque étrangère qui avaient été dissimulées dans un envoi importé au port de Nhava Sheva, ou encore les graines de pavot cachées dans un envoi importé au port de Chennai. Ce ne sont là que quelques exemples parmi beaucoup d’autres.
Le modèle a montré qu’il peut renforcer les capacités des douanes à lutter efficacement contre la contrebande. L’architecture multicouches et la boucle de rétroaction continue ont permis de garantir que le modèle demeure dynamique et pertinent. Tandis que le paysage des menaces ne cesse d’évoluer, ce modèle pourrait bien redéfinir les paradigmes de la lutte contre le commerce illicite et nous permettre de mieux protéger nos économies et nos sociétés de la menace de la contrebande.
En savoir +
sruti.vijayakumar@gov.in
Mramesh.irs@gov.in
[1] Une donnée bruitée est une valeur qui semble être correcte, mais qui en réalité, ne l’est pas.