

Un sondage mené en 2020 auprès des membres du groupe de spécialistes douaniers sur LinkedIn offre peut-être une appréciation plus réaliste du nombre d’heures nécessaires pour maîtriser le classement dans le SH : 92 % ont répondu « au moins 100 heures ». Plus d’un tiers a même déclaré qu’il faudrait pouvoir bénéficier, pour bien faire, de plus de 500 heures de formation sur le SH.
La question qui se pose dès lors est la suivante : si les riches bibliothèques d’informations et de formations ne constituent pas une solution pratique au problème très réel des erreurs de classement dans le SH, la technologie peut-elle y contribuer ? La réponse générale est oui. Toutefois l’efficacité d’un outil d’aide au classement tarifaire dépendra du type de technologie appliquée. À l’heure actuelle, trois grands types de technologie sont utilisés: les moteurs de recherche par mots-clés, les systèmes experts et les algorithmes d’apprentissage automatique.
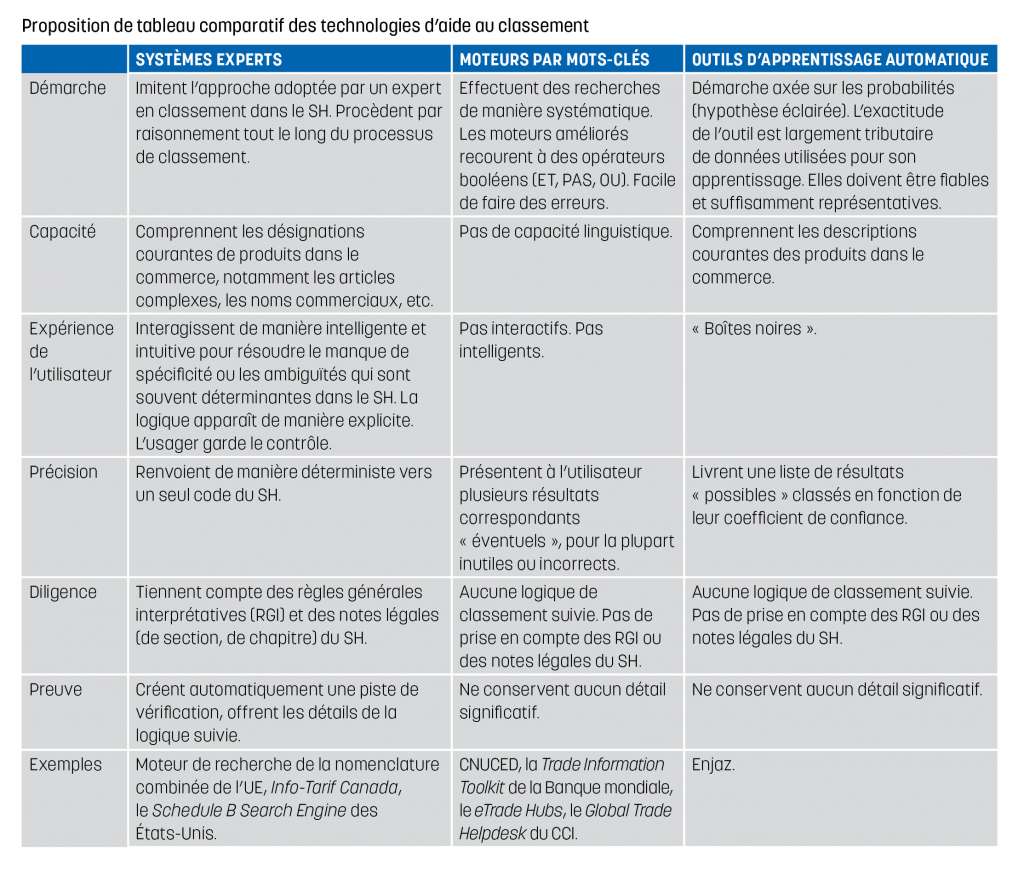
Les outils de recherche par mots-clés
Technologie la plus couramment utilisée, les moteurs de recherche par mots-clés se trouvent, sous une forme ou une autre, dans les systèmes de gestion douanière, dans les guichets uniques électroniques et les portails d’informations sur le commerce. On peut citer ici le SYstème DOuaNIer Automatisé (SYDONIA), conçu par la CNUCED, le portail d’information sur le commerce du Vietnam, conçu par la Banque mondiale, ou encore le Market Access Map et le Rules of Origin Facilitator du CCI.
Les outils de recherche par mots-clés s’efforcent d’appairer les mots ou les phrases que les usagers soumettent avec ceux du document-cible. Malheureusement, ce processus comporte de sérieuses lacunes et constitue le talon d’Achille de ces outils. Si l’usager ne saisit pas un mot ou un libellé qui est explicitement utilisé dans la nomenclature, le moteur ne proposera aucun résultat. Une désignation tout à fait courante d’une marchandise pourra n’aboutir à aucun résultat. C’est le cas par exemple pour « aliment pour nourrisson » ou « minuterie à œufs », auxquels le SH se réfère respectivement sous le libellé de « préparations alimentaires composites homogénéisées » et d’« appareils de contrôle du temps et compteurs de temps ». Les moteurs de recherche par mots-clés exigent que l’utilisateur connaisse un tant soit peu la terminologie souvent absconse du Système harmonisé pour proposer la moindre réponse.
Lorsqu’un mot correspondant est reconnu, ces outils affichent souvent de longues listes de correspondances « possibles » complètement inutiles et erronées. Choisir demande là aussi à l’usager d’avoir une certaine maîtrise du processus de classement et du contenu de la nomenclature afin de déterminer le code le plus adapté parmi les nombreuses « possibilités » proposées. Il devient, d’ailleurs, presque impossible d’assurer l’exactitude du classement lorsque le code approprié est associé à une position ou à une sous-position résiduelle (portant le libellé « autres » pour désigner le produit dans le SH).
Certains moteurs de recherche par mots-clés ont été améliorés à l’aide d’opérateurs booléens, qui sont de simples vocables (ET, OU, PAS, ET PAS) utilisés pour combiner des mots-clés dans une recherche ou pour les en exclure, et dès lors susceptibles de rendre des résultats plus pertinents. D’autres ont ajouté des synonymes à leur moteur pour les aider à combler la profonde brèche qui sépare la terminologie utilisée dans le commerce et le jargon du SH. Il n’en reste pas moins vrai, toutefois, que les moteurs de recherche par mots-clés ne sont capables de donner de résultats que s’ils retrouvent un terme correspondant exactement ou en partie au mot-clé recherché dans le document ou la base de données visés.
Une recherche concernant le mot « ordinateur » dans le système électronique sur le commerce du gouvernement de la Barbade offre un exemple typique du problème posé par les moteurs de recherche par mots-clés. L’outil propose deux correspondances possibles, toutes deux erronées : le 4821.10.00.900 (« porte-prix, étiquettes sur-imprimées, étiquettes imprimées par ordinateur ou par copieur ») et le 4821.90.00.900 (« autres étiquettes de prix, sur-imprimées ou imprimées par ordinateur ou copieur »). Pour retrouver le code adéquat couvrant les « ordinateurs », le déclarant doit savoir que, dans la nomenclature du SH, de tels appareils sont décrits comme étant des « machines automatiques de traitement de l’information ».
Les moteurs de recherche par mots-clés ne peuvent donc pas vraiment être considérés comme des outils d’aide au classement dans la mesure où ils n’ont pas été conçus expressément à des fins de classement dans le SH. Ils ne tiennent compte ni des règles générales interprétatives (RGI) ni des notes légales et ne les appliquent donc pas.
Les systèmes experts
Les systèmes experts sont des outils basés sur l’intelligence artificielle (IA) qui, dans le cadre de la discussion qui nous occupe, ont été construits spécifiquement dans le but de remédier aux problèmes spécifiques associés au classement dans le SH. Ces problèmes ont notamment trait :
Les systèmes experts qui ont été conçus et déployés en tant qu’outils d’aide au classement dans le SH (par exemple, le Census Bureau Schedule B Search Engine des États-Unis, Info-Tarif Canada et le moteur de recherche Warenverzeichnis Online du gouvernement fédéral allemand) ressemblent à des moteurs de recherche par mots-clés ordinaires mais ils n’ont rien d’autre en commun. En effet, ils exploitent des connaissances spécifiques, des règles empiriques et des outils de raisonnement pour procéder au classement de la marchandise de manière intelligente et intuitive et ne proposer qu’un seul code.
Une recherche sur le mot « tire-bouchon » dans le moteur de recherche de la nomenclature combinée de l’Union européenne illustre bien les avantages d’un outil d’aide au classement basé sur un système expert. L’outil reconnaît que le terme « tire-bouchon » n’est pas assez spécifique et pose alors la question de savoir s’il fonctionne par voie mécanique, électromécanique ou par tout autre moyen. En fonction de la réponse donnée, il proposera déjà un code du SH ou posera une ou plusieurs autres questions si besoin. Le processus de classement a été automatisé jusqu’à un certain point mais le déclarant en conserve le contrôle intégral. L’outil procède par déduction et supposition et répond à ce que l’usager aura spécifiquement saisi, offrant au final une recommandation qui aura été générée compte tenu et par application des RGI et des notes légales du SH.
Les outils d’aide au classement basés sur les systèmes experts ont prouvé leur efficacité à formuler des recommandations cohérentes et exactes et ils permettent aux débutants d’apprendre plus rapidement à utiliser le SH. Une administration des douanes nationale a indiqué que le déploiement de son outil d’aide au classement lui avait permis d’améliorer la qualité des données des déclarations de 4 6%, l’exactitude du classement de 22 % et la conformité fiscale de 29 % en deux ans.
Les algorithmes d’apprentissage automatique
La plus récente des technologies appliquées au sujet dont nous discutons est l’apprentissage automatique. Il s’agit essentiellement d’une forme d’intelligence artificielle qui formule des prévisions à partir de données. Cette technologie utilise les algorithmes et les modèles statistiques pour apprendre et pour s’adapter en conséquence, sans exiger d’instructions explicites au niveau de la programmation, ce qui en fait un outil particulièrement puissant. L’apprentissage automatique est en outre stochastique, c’est-à-dire qu’il suit un processus reposant sur des variables aléatoires qui permet de formuler des analyses statistiques mais non des prévisions précises, de sorte que les estimations générées par les algorithmes d’apprentissage automatique sont, en l’essence, des hypothèses éclairées.
Les données utilisées pour « former » le système sont un facteur essentiel de succès. Pour faire en sorte que l’algorithme d’apprentissage automatique soit digne de foi, il est indispensable de veiller à utiliser une quantité suffisante de données représentatives et étiquetées de manière fiable.
Dans un article publié dans la Harvard Business Review en 2018, Thomas Redman remarquait que le « garbage in, garbage out » (si l’on encode des mauvaises données, on aboutit forcément à de mauvais résultats) avait sévi dans le domaine de l’analytique et de la prise de décisions pendant des générations. Or, souligne-t-il, il convient de l’éviter tout particulièrement dans le cas de l’apprentissage automatique : « Les exigences de qualité de l’apprentissage automatique sont exorbitantes et de mauvaises données peuvent réapparaître furtivement, dans toute leur horreur, par deux fois : tout d’abord dans les données historiques utilisées pour « former » le modèle prédictif, ensuite dans les nouvelles données utilisées par le modèle afin de prendre des décisions futures ».
Aux fins du classement dans le SH, « l’étiquetage » fait référence à la mise en correspondance exacte entre les descriptions narratives des produits commerciaux et les codes du SH – une tâche qui peut être menée soit manuellement (sous supervision), soit automatiquement (sans supervision). Reste encore à savoir s’il est possible ou non de construire un modèle digne de foi, qui puisse être utilisé de manière universelle sur le vaste ensemble des données émanant des déclarations. En effet, les déclarants décrivent leurs marchandises de manière infiniment diverse et personnelle et seuls les modèles d’apprentissage automatique construits sur des données de formation très spécifiques et contrôlées peuvent être utilisées.
Un exemple d’outil d’aide au classement disponible au public et qui prétend utiliser un algorithme d’apprentissage automatique est l’outil de classement selon les codes du SH utilisant l’intelligence artificielle du portail douanier Enjaz sur le commerce. L’outil Enjaz lit les descriptions de marchandises complexes et renvoie une liste de possibles codes correspondants ainsi que des facteurs de probabilité, qui sont censés donner aux usagers une idée du niveau de fiabilité des codes proposés.
Une recherche sur un « support pour moteur automobile, en acier » dans l’outil Enjaz, par exemple, propose deux codes incorrects : le 8708.99 et le 8409.99 (le classement correct est le 8302.30). Il est de surcroît un tant soit peu inquiétant que le taux de probabilité attribué au 8708.99 soit de 95,76 %.
Les outils qui exploitent l’apprentissage automatique sont indubitablement plus intelligents que ceux qui reposent sur des opérateurs de mots-clés ; ils présentent, toutefois, nombre des mêmes défaillances. Ils exigent encore et toujours de l’utilisateur une compréhension approfondie et détaillée des règles qui gouvernent le classement dans le SH et une familiarité avec la nomenclature du SH en soi. Par ailleurs, les modèles d’apprentissage sont constamment en phase de « réapprentissage » et les résultats qu’ils livrent peuvent donc changer avec le temps, ce qui est plus inquiétant et en font des outils plus bancals que les outils utilisant des mots-clés.
Conclusion
Les outils d’aide au classement constituent un élément important des systèmes modernes de gestion douanière, des portails d’informations sur le commerce et des guichets uniques électroniques. Les diverses technologies offertes par ces systèmes sont tellement différentes qu’elles peuvent difficilement être comparées. Malgré tout, pour une administration des douanes, la technologie choisie sera déterminante.
Afin d’apporter une valeur pratique réelle à l’opérateur commercial ordinaire, les outils d’aide au classement dans le SH doivent être intuitifs, fiables et disponibles.
Des trois principales technologies utilisées pour aider à classer les marchandises dans le SH, les systèmes experts semblent répondre au mieux aux objectifs souvent contradictoires de la facilitation des échanges et du contrôle douanier. La facilitation est assurée grâce à une expérience de l’utilisateur plus satisfaisante, les usagers pouvant décrire leurs marchandises dans un langage commercial de tous les jours. Les outils sont intelligents et conviviaux ; ils renvoient toujours vers un seul code du SH ; enfin, ils laissent le contrôle ultime du classement entre les mains de l’utilisateur. La conformité est assurée de manière cohérente et déterministe à travers l’examen et l’application automatiques de règles générales interprétatives et de notes légales complexes.
Quoi qu’il en soit, les outils ne restent au final que des outils. Ils sont conçus pour apporter une aide aux fins du classement, non pour effectuer le classement en soi. Il va donc sans dire que les résultats qu’ils proposent n’auront de valeur n’auront de valeur que s’ils sont mis dans les bonnes mains. Une tronçonneuse entre les mains d’une personne lui permettra de construire une superbe cabane en bois. Entre les mains d’une autre, elle pourrait bien faire tomber un arbre sur cette même cabane !
En savoir +
randy.rotchin@avalara.com