

In the United States, for example, the Department of Commerce uses identifiers called export control classification numbers (ECCNs) to categorize items that are subject to export control regulations. These ECCNs predominantly contain strategic goods. US Customs and Border Protection uses the Harmonized Tariff Schedule of the United States (HTSUS), which is based on the international Harmonized System (HS). Attempting to link ECCNs with their HTS codes is a difficult task. The HTS-ECCN relationships are rarely one-to-one. A strategic good could be shipped under a host of HTS codes, and an HTS code could contain multiple ECCNs. Moreover, many controlled items involve dual-use industrial and scientific equipment or material defined by technical specifications in technical documents, and HS code descriptions hardly ever contain such specifications.
The combination of these factors makes it a challenge for State authorities to detect potential illicit transfers of strategic goods. Screening transactions based on inexact, static correlation tables between HS codes and codes used in control lists, or based on information on parties to the transactions, is not sufficient for a comprehensive STC system.
The methodology proposed in this article suggests utilizing the vast amounts of transaction data which every government collects, along with machine learning, i.e. the process of teaching a computer system how to make accurate predictions when fed data.
Machine learning and international trade
Identifying transactions involving strategic goods lends itself to solutions developed for a common machine learning problem: outlier detection. Outlier detection is used in a wide variety of applications, such as credit card fraud, suspicious traffic in cyber security, disease detection, and many other problems where the target is behaviour outside the norm. Since strategic trade is such a small proportion of overall trade, transactions involving controlled goods can be considered outliers. Such transactions are not only uncommon, but they are also likely to stand out from others since the goods traded are generally technically sophisticated materials and equipment. This can present itself through higher unit values, lower quantities, specific trading partners and other characteristics that distinguish strategic good transactions from others.
The following section outlines a basic approach for using machine learning to identify transactions involving strategic goods but not declared as such. It uses historical trade data on transactions of goods with and without ECCNs. The models created as an outcome of the process are then applied to new transactions to provide a predicted probability that they relate to a specific strategic good. This is a supervised learning approach; one is training models on historical data where one already knows the outcome – the shipment has an ECCN and contains a strategic good or it does not have an ECCN and does not contain a strategic good – and applying it to new cases[1]. A short summary of the methodology is outlined below. For convenience, the codes in the HTSUS are referred to as HS codes.
Methodology
This approach creates a machine learning model for a specific strategic good, based on its ECCN. The process can be repeated to create a portfolio of models that can be used to classify transactions involving many different strategic goods. The first step in the process is to identify the strategic good for modelling, based on its ECCN.
After the ECCN is selected, data for transactions with this ECCN in the shipping documentation would be pulled together for a specified timeframe. A wide range of features can be selected to develop this model, including the HS code, exporters/recipients, destination, weight, quantity, value, etc. Once this data is gathered, one would create a “basket” of the different combinations of the ECCN and HS codes. This basket would show how often a particular HS code is utilized by exporters for transactions involving the ECCN (i.e. 45 per cent of transactions involving strategic goods classified under ECCN X were shipped using HS code Y). This allows one to identify the HS codes that are actively being used by exporters for transactions involving a strategic good, as opposed to a correlation table that says what the HS code for a strategic good should be.
The HS-ECCN baskets will often contain HS codes that are used for a transaction at a very low rate. To avoid the inclusion of too many edge cases in the next step, a cutoff correlation percentage is designated to determine the most relevant HS codes in use for the particular strategic good.
Once the high correlation HS codes are identified, data would be pulled from all transactions with these HS codes without an ECCN for the same time period from which one drew the transactions with ECCNs. This assembles the universe from which one can model the characteristics of trade in the strategic good.
The number of transactions involving strategic goods is greatly outnumbered by those that do not. In other words, there is a majority class (those that do not have an ECCN) and a minority class (transactions that have an ECCN). In machine learning, highly imbalanced data like this can have adverse effects on modelling and traditional measures of performance. To adjust for this, the transaction data should be resampled to bring the minority class more in balance with the majority class. For this purpose, this methodology uses the Synthetic Minority Over-Sampling Technique (SMOTE)[2], which identifies similar examples in the minority class and creates new instances by combining the features of an existing case with features of its neighbours. Rather than duplicating transactions to oversample, this technique provides new, synthetic examples of the minority class.
Once prepared, the data is ready to be used to create a model. Here, Random Forest is used to predict whether a transaction involves a strategic good. This algorithm creates many decision trees based on randomly selected features and data samples to determine whether a transaction is classified as involving the strategic good or not. The outcome of each decision tree is then compiled and, as one is dealing with a binary classification, the final classification is that chosen by the majority of the decision trees. Figure 1 presents a simplified representation of the Random Forest algorithm.
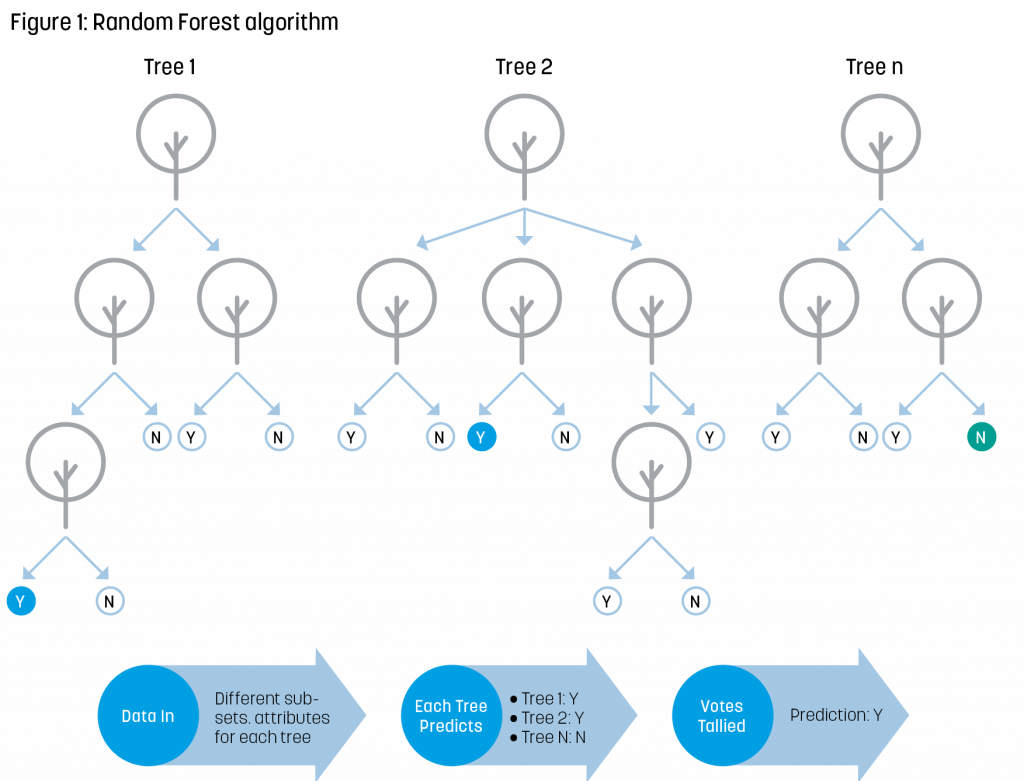
The algorithm would be trained on a subset of data, and performance would be measured against another subset reserved as a test set. Based on the results, parameters or features could be changed to increase performance. Once the approach has been tested for a particular strategic good related to a specific ECCN, it can be used iteratively to create models for a broad portfolio of strategic goods and applied as new data arrives.
Benefits and potential applications
Given the data-dense nature of international trade transactions, State authorities around the world are in an excellent position to exploit advances in machine learning to improve risk analysis, enforcement and outreach. As more transactions are recorded every day, the models created to classify strategic goods can improve, be adjusted, and reworked under the same methodological construct. In addition, since this approach proposes the use of State-centric data, the models will inherently be designed to identify strategic goods in the context of that State, taking into account geography, trading partners, and industrial capabilities. The recent expansion of distributed computing and cloud-based services allows for State authorities to analyse and create models for a much larger portion of data than could be handled even five to ten years ago.
The methodology described in this article has a wide variety of useful applications. From an enforcement perspective, this approach would allow for better profiling of transactions using real-world data and for optimizing inspections or end-use checks. Moreover, modelling based on a select set of high priority strategic goods could enable Customs to enhance resource allocation and provide data-based justifications for further scrutiny. This approach would also allow for States to better understand common trade flows for strategic goods and identify common end-use destinations or transshipment points.
In addition, the methodology could also support internal compliance programmes and be used to design outreach efforts that would improve STC efficiencies. Indeed, a key challenge to the enforcement of export controls in many countries relates to outreach and raising awareness. The private sector needs assistance in identifying, managing and mitigating risks associated with strategic goods, and in ensuring compliance with regulations. Based on the models trained through existing data, it would be possible to identify transactions that fit the profile of a strategic good but for which no licences were requested by the importer or the exporter. Customs could then contact the entities involved in these transactions to start a dialogue and propose training on export control regulations. It could also identify common trade flows for these unlicensed transactions that meet the strategic good profiles, and initiate international outreach and training.
Since the methodology uses a basket of HS codes, it could also be used to complement existing HS-ECCN correlation tables and improve these correlations system-wide. First, the HS-ECCN baskets add “weight” to correlations based on historical transactions involving strategic goods. It can identify which HS codes are used in practice and at what rate, adding a layer of detail to the one-to-many or many-to-many static correlation tables. Second, the HS-ECCN baskets would identify common correlations and misclassifications of strategic goods that could be used for outreach efforts or to propose future HS amendments to bring the HS and ECCNs closer together.
As more data is collected and outreach and enforcement efforts become more targeted, the machine learning models would be likely to increase in performance, creating a cycle of improvement. Leveraging the large amount of data already collected by States and machine learning models could improve STC systems. Focusing not only on enforcement, but also using this approach for outreach, could improve detection capacities and foster a more secure international trading system.
More information
chris.nelson28@gmail.com
For further details on the methodology used, see the author’s article in the World Customs Journal (Volume 14, Issue 2, September 2020)
[1] “Knows the outcome” is a generalization. This is based on the quality of the data collected, adherence to legal licensing procedures, and declarations of ECCNs on shipment documentation. There are intentional and unintentional errors resulting from this, but this model uses the correct declarations to create a model and then apply them to other transactions, which is designed to uncover these issues.
[2] For details on SMOTE, see Chawla et al., Journal of Artificial Intelligence Research, Vol. 16 (2002), pp. 321-357.