
Au moment de la rédaction du présent article, l’OMC comptait 164 membres, l’Afghanistan étant le dernier État à avoir rejoint l’organisation en juillet 2016. Outre les membres de l’OMC, plusieurs autres pays ont choisi d’adopter volontairement l’Accord en vue de déterminer la valeur en douane. Afin de tenir les engagements internationaux pris par leur pays, les douaniers appliquent généralement six méthodes pratiques pour déterminer la valeur en douane des marchandises. Si la valeur transactionnelle est remise en cause, il est entendu que les deux méthodes les plus efficaces pour estimer la valeur probable d’un article sont la comparaison de l’envoi concerné à la valeur transactionnelle de marchandises identiques ou à la valeur transactionnelle de marchandises similaires entrant sur le territoire national. Habituellement, l’une et l’autre de ces comparaisons sont facilitées par la mise sur pied d’une base de données en matière d’évaluation.
Cependant, la gestion et l’application d’une base de données sur l’évaluation implique de nombreuses contraintes aux niveaux administratif et technique. Un tel dispositif exige entre autres :
Chacune de ces pratiques comporte des défis. Les experts de l’évaluation en douane, par exemple, sont plutôt rares et la mise à jour d’une base de données exige de mobiliser de nombreuses ressources. Il est difficile de demander aux agents en douane qu’ils appliquent les codes tarifaires spécifiques, même pour la petite partie du tarif qui semble poser le plus grand nombre de problèmes en matière d’évaluation. Étant donné que les données sur les prix de référence se fondent généralement sur les pays d’importation, il est nécessaire de trouver des données qui soient pertinentes pour son propre pays (les données de prix de référence des États-Unis seront d’une moindre utilité ailleurs dans le monde).
Par ailleurs, si les marchandises n’ont pas été classées convenablement, les données sur les prix de référence tirées de la base de données d’évaluation qui sont ensuite appliquées à un article peuvent être incorrectes. Les experts en évaluation ne sont pas pour autant des experts en classification tarifaire ; or, les problèmes les plus courants en matière de sous-évaluation et de mauvais classement sont quelque peu liés. Il est donc difficile de s’attaquer aux uns sans tenir compte des autres.
Apprentissage automatique
L’apprentissage automatique, c’est-à-dire le processus par lequel un système informatique apprend à formuler des prévisions précises lorsqu’il est alimenté en données, peut s’avérer fort utile à cet égard. Pourtant, ce domaine semble encore être peu connu des douanes et c’est pourquoi nous aimerions, dans les paragraphes ci-après, expliquer plus en détail comment fonctionnent les ordinateurs dotés d’un outil de modélisation prédictive.
Aujourd’hui, les modèles prédictifs peuvent déterminer le classement tarifaire et la valeur d’une marchandise sur la base des données entrantes reprises dans le tableau 1. Ces modèles fonctionnent même si une partie de l’information n’est pas fournie, mais plus ils sont alimentés en information, plus ils sont précis.

Comme le montre le tableau 1, les modèles analytiques auxquels nous nous référons prennent bien plus d’éléments en considération qu’une simple comparaison de la valeur déclarée et du pays d’origine afin de déterminer la valeur CAF. Les modèles peuvent être conçus pour analyser plusieurs langues et les algorithmes utilisés prennent en compte tellement de facteurs qu’ils dépassent facilement les capacités analytiques des meilleures bases de données ou des plus grands experts de l’évaluation en douane quand ils sont appliqués à grande échelle.
Les grappes de valeurs acceptables pour des marchandises identiques ou comparables et les valeurs des produits tombant en dehors de la marge acceptable sont répertoriées et les résultats présentés sous forme de graphique ou de schéma en grappe interactif, ce qui permet ensuite à l’inspecteur en douane de visualiser facilement l’analyse afin de déterminer les mesures à prendre en aval.
Ce qu’il faut chercher dans la description des marchandises
Les modèles recherchent un certain nombre d’indicateurs dans une description de marchandises afin d’identifier les produits en présence et de détecter toute anomalie ou tentative de dissimulation.
Le modèle d’apprentissage automatique examine toutes les phrases et les mots dans la description des marchandises et les utilise pour revoir, à la hausse ou à la baisse, un certain montant qu’il a préalablement établi pour une marchandise donnée, en fonction des importations passées d’articles similaires. Qui plus est, les modèles fonctionnent avec plusieurs langues, c’est-à-dire que les mots, les phrases ou encore les expressions en espagnol ou en chinois peuvent être comparés à leurs équivalents en anglais. Une description de marchandises établie en utilisant deux langues peut être interprétée aussi efficacement qu’une description dans une seule langue. Le même appariement plurilingue est appliqué s’agissant de noms d’exportateurs, d’importateurs et de destinataires et une référence telle que ‘Honda Motor Co.’ sera donc mise en correspondance avec ‘本田技研工業’.
Le résultat
Que se passe-t-il une fois que le système informatique a effectué l’analyse sur la base de ces modèles ?
Mauvaise classification – Pour chaque article déclaré, le système attribue un coefficient de probabilité, c’est-à-dire un chiffre entre zéro et un, pour indiquer si le code SH est correct. Il fournit également une liste comprenant jusqu’à cinq codes différents du SH qui pourraient s’appliquer aux marchandises en cause, avec une mesure de probabilité. En d’autres termes, l’agent qui examine l’information peut déterminer avec précision si le code déclaré est correct ou pas, et, si tel n’est pas le cas, le code qui devrait être attribué. Tout cela semble bien beau mais, évidemment, la douane s’intéresse surtout aux cas de classement incorrect, où les taxes et droits exigibles qui s’appliquent aux codes du SH déclarés diffèrent de ceux s’appliquant au code considéré comme probable ou correct. Le système calcule donc automatiquement les nouveaux droits et taxes exigibles si ce code était utilisé, afin que la douane puisse déterminer rapidement s’il est rentable de constituer un dossier pour classement incorrect à l’encontre de l’importateur ou pas.
Sous-évaluation – Le système prédit également la valeur CAF pour chaque article déclaré en fonction des informations fournies, notamment sur la base des importations passées pour ce type de produits. Les transactions plus récentes sont davantage prises en compte pour les types de marchandises dont la courbe de décroissance de prix est plus marquée, comme dans le cas d’articles qui perdent leur valeur rapidement au vu de leur obsolescence, tels que les derniers modèles de téléphones portables. Le système recalcule également les droits et taxes exigibles sur la base de cette « nouvelle » valeur. Le système comprend également une fonction facultative qui lui permet de mettre en cause tant la valeur CAF déclarée que le code SH déclaré, s’il estime être en présence d’un cas tant de sous-évaluation que de classement incorrect.
Pays d’origine incorrect – Le système peut déterminer précisément si le pays d’origine déclaré est correct ou pas, sur la base de l’historique des importations depuis ce pays pour ce type de marchandises. Si le pays d’origine est considéré comme inhabituel, le système établira une liste des cinq pays d’origine les plus probables, chacun étant susceptible d’être le bon. Les opérateurs commerciaux peuvent essayer de cacher le pays d’origine pour profiter de droits préférentiels ou des dispositions d’un accord de libre-échange. Il s’agit d’un élément de plus à prendre en considération pour le contrôle de l’évaluation.
Ainsi, quelle que soit la transaction, le système peut déterminer si les marchandises sont susceptibles d’avoir été mal classées et/ou sous-évaluées, et/ou si le pays d’origine est inexact. Les recettes potentiellement perdues sont également calculées afin que la douane puisse rapidement décider si le cas mériterait qu’elle s’emploie à construire un dossier à l’encontre de l’importateur ou pas.
Et ce n’est pas tout…
Le système peut aussi déterminer rapidement le montant de la garantie (par exemple, la caution) que l’opérateur devrait acquitter à la douane avant la mainlevée des marchandises, pour autant que le code douanier prévoie ce genre de procédures. Rappelons que cette possibilité est inscrite dans la Convention de Kyoto révisée de l’OMD pour la simplification et l’harmonisation des régimes douaniers, dans sa norme 3.43 (Formalités de dédouanement et autres formalités douanières) :
« Lorsqu’une infraction a été constatée, la douane accorde la mainlevée sans attendre le règlement de l’action administrative ou judiciaire sous réserve que les marchandises ne soient pas passibles de confiscation ou susceptibles d’être présentées en tant que preuves matérielles à un stade ultérieur de la procédure et que le déclarant acquitte les droits et taxes et fournisse une garantie pour assurer le recouvrement de tous droits et taxes supplémentaires exigibles ainsi que de toute pénalité dont il pourrait être passible. »
Conformément à cette disposition, même s’il existe une suspicion d’évasion fiscale, les marchandises devraient être libérées si aucun autre élément ne vient entraver leur mainlevée et une mesure administrative devrait être prise plus tard pour recouvrer les droits et taxes dus. Cela étant, dans de nombreux pays, cette procédure ne peut être mise en œuvre dans la mesure où la douane met énormément de temps à déterminer le montant de la garantie qui devrait être déposée avant la mainlevée, en attendant qu’une enquête approfondie soit menée. Par conséquent, la décision finale en matière d’évaluation est souvent prise avant l’octroi de la mainlevée en rapport avec la déclaration contentieuse… et cela peut prendre quelques jours. De telles situations signifient un coup d’arrêt dans la chaîne logistique, notamment pour les autres marchandises qui font partie du même envoi, si l’administration n’est pas en faveur de l’octroi d’une mainlevée partielle.
Reconnaître les erreurs involontaires
Il est courant que les opérateurs commerciaux ou les agents en douane commettent des erreurs lorsqu’ils indiquent des valeurs, des poids et des mesures sur la déclaration en douane. Les modèles analytiques peuvent repérer les cas où une déclaration contient des informations incorrectes et/ou ambiguës, ou une description des marchandises qui pourrait induire en erreur ; ils signalent alors que la déclaration devrait faire l’objet d’un contrôle documentaire et devrait éventuellement être corrigée, tout en indiquant le(s) bien(s) en cause et le contenu où ils relèvent une possible coquille.
Question d’échelle
Il arrive souvent que les équipes chargées des contrôles a posteriori soient un tant soit peu en sous-effectifs, ne disposent pas des ressources nécessaires ou n’aient pas accès aux outils analytiques leur permettant de faire leur travail. Les modèles d’apprentissage automatique que nous abordons dans le présent article peuvent être utilisés pour analyser les données des déclarations en douane sur les deux ou trois dernières années, afin d’identifier les opérateurs commerciaux qui sont potentiellement le plus en faute en matière de sous-évaluation et de fausse classification. Les équipes de CAP peuvent ainsi cibler les opérateurs et les types de marchandises susceptibles de ramener les plus gros montants de recettes dans les caisses publiques si les négociants fautifs sont poursuivis en justice. De telles mesures auraient également un effet dissuasif. Le « retour sur investissement » peut se mesurer en jours, voire en semaines.
Question de précision
Les utilisateurs des outils analytiques mentionnés ici font état d’un taux d’exactitude de près de 85 %, et ce pourcentage ne cesse de s’améliorer. Si les résultats de l’analyse ne sont pas concluants ou soulèvent des incertitudes, le système le signalera à la douane qui pourra choisir soit de ne pas en tenir compte soit de demander aux importateurs de fournir des informations moins ambiguës.
Prix de transfert et le test des parties liées
Les faits semblent indiquer que les transactions transfrontalières entre parties liées représentent à peu près 30 % du commerce mondial. Conformément aux Principes directeurs de l’OCDE, une transaction entre parties liées doit répondre au principe « des conditions de pleine concurrence », ce qui équivaut à dire que les conditions (de prix, les marges bénéficiaires, etc.) des transactions entre parties liées devraient être les mêmes que celles qui existeraient entre deux parties indépendantes, pour une transaction similaire dans des conditions semblables.
Il est généralement assez facile d’identifier les exportateurs et le destinataires finaux, puisqu’ils doivent apparaître normalement sur la déclaration de marchandises. Toutefois, la douane doit envisager toutes les manières dont un exportateur et un importateur liés peuvent être décrits, afin d’établir une carte des parties liées.
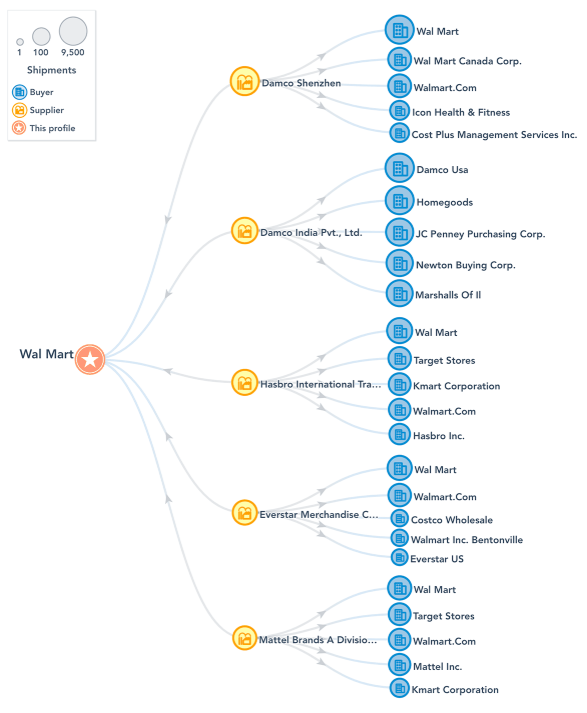
Voici, en guise d’exemple, une liste de quelques parties liées à Honda Corp. en Malaisie :
Et en Corée :
Il est clair que si le nom de Honda apparaît dans l’appellation tant de l’exportateur que de l’importateur, le système de traitement automatique du langage permettra de relever que la transaction a lieu entre des parties liées, mais qu’en est-il d’une transaction entre UMW Industrial Power en Malaisie et SDN Company Ltd en Corée ? Comment déterminer s’il s’agit d’une transaction entre parties liées ?
Le Trade Data Network ou Réseau de données sur le commerce
Nous disposons, pour près de 50 % des envois traversant les frontières, des données sur le nom des sociétés impliquées dans la transaction à l’exportation et à l’importation, ainsi que la liste des directeurs et des actionnaires. Pour créer une telle base de données mondiale d’enregistrement des entreprises, il a fallu non seulement les obtenir mais aussi les nettoyer, les relier et harmoniser les jeux de données décrivant les transactions et les réseaux de transport. Les relations entre sociétés-mères et filiales des entités liées ont également dues être cartographiées. Les données publiques et celles disponibles dans le commerce ont été appariées afin de créer un jeu de référence sur les réseaux et les flux mondiaux, que nous avons appelé le Trade Data Network ou Réseau des données sur le commerce.
Lorsque les données contenues dans une déclaration en douane sont croisées avec les données du Réseau, les transactions entre parties liées apparaissent clairement. Le Trade Data Network peut identifier les sociétés écrans qui peuvent avoir été créées pour réaliser quelques envois seulement, avant de mettre la clé sous le paillasson, en examinant le nom des directeurs ou le mode opératoire suivi pour la transaction : par exemple, un exportateur vient de lancer son activité de commerce pour un type de produit dans un nouveau pays et un importateur en a commandé une quantité pour le moins surprenante. Bien que le Trade Data Network soit un produit relativement nouveau, ses utilisateurs obtiennent déjà des résultats encourageants leur permettant de cartographier les organisations criminelles internationales.
Valeur ajoutée
Il existe sur le marché des applications informatiques qui fusionnent des données afin d’offrir un aperçu centralisé d’informations provenant de sources disparates. Ces applications peuvent être incorporées aux systèmes douaniers existants et mettre en lumière des liaisons entre parties et des schémas de fraude potentielle. IBM I2 Analyze ou encore Palantir sont deux exemples d’environnements créés à cet effet.
Toutefois, afin d’utiliser ces outils, les administrations des douanes doivent disposer de sources de référence et de données transactionnelles adéquates ou encore de renseignements exploitables ; ou alors, elles doivent avoir les ressources nécessaires pour transformer les données qu’elles recueillent dans la pratique en un format qui puissent être analysé par ces systèmes de manière intelligente. Dans le meilleur des cas, les douanes peuvent avoir accès à leurs propres données et, tout au plus, à celles de leurs voisines, mais elles ne jouiront généralement pas d’une vision d’ensemble du paysage commercial mondial. Il est clair que les douanes peuvent faire appel à une tierce partie pour les aider, contre rémunération, dans le processus de saisie, de transformation et d’analyse des informations, mais ces services sont coûteux et chronophages et peuvent être sources d’erreurs. Concrètement, cette approche peut être utile pour les États qui disposent des fonds et des ressources nécessaires pour construire de vastes lacs de données, pour engager des experts afin qu’ils construisent des modèles reliant les jeux de données, et pour former des analystes hautement qualifiés capables de naviguer à travers cet arbre de connaissances afin de tirer des renseignements utiles.
Le Trade Data Network se distingue des autres outils dans la mesure où il contient déjà un vaste ensemble de renseignements précieux provenant du monde entier, qu’aucun pays ne pourrait vraiment constituer à lui seul. En schématisant les données douanières d’un pays et en les superposant sur les données des flux commerciaux mondiaux, les analystes douaniers peuvent rapidement détecter des anomalies, et cela sans qu’ils aient dû collecter et saisir des renseignements dans leur système.
Le Réseau n’est pas vraiment un produit mais bien un système de renseignement qui est fourni avec des données sur des transactions normales et anormales. En comparant les transactions entrantes à la « norme », les analystes peuvent détecter les quelques transactions qui sont anormales. En superposant automatiquement les données concernant un nouvel envoi sur les réseaux de liens commerciaux existants, nous pouvons repérer les transactions entre parties liées ou les transactions entre de nouvelles parties, ou, plus simplement, les transactions qui ne sont pas logiques. En triant automatiquement les milliers de déclarations en douane que reçoit un petit pays ou un État de taille moyenne au cours d’une journée normale, l’analyse effectuée par le Trade Data Network aide à mettre le doigt sur le petit nombre de transactions qui sont vraiment anormales.
Les avancées dans l’informatique en nuage, dans le traitement automatique du langage naturel et l’apprentissage automatique permettent aujourd’hui de mettre cet ensemble de renseignements exploitables à la disposition de pays à revenu faible et moyen, et ce à un prix abordable.
Apprendre des autres
L’Accord de l’OMC sur l’évaluation en douane établit que les valeurs devraient être comparées aux importations passées ou comparables dans un même pays. Les premiers résultats indiquent qu’il est possible de mettre sur pied un modèle qui tire les enseignements des données d’un pays et est capable d’appliquer les conclusions tirées à un pays semblable dans la même région. En somme, plus les administrations douanières adopteront cette démarche moderne pour résoudre les problèmes pratiques de l’évaluation en douane, plus elles seront susceptibles de renforcer leur capacité réciproque à détecter les fuites de revenus, non pas en partageant les informations contenues dans les déclarations à travers les frontières mais bien en partageant les formules de calculs et les seuils établis par leurs modèles d’évaluation de la valeur. Parmi les exemples de groupements de pays qui pourraient mutuellement tirer parti d’un tel échange, citons :
Prochaines étapes
Une fois qu’il est avéré qu’un exportateur ou un importateur est en infraction, il est facile de schématiser les liens commerciaux existant entre les personnes physiques ou morales concernées présentant un intérêt pour la douane et de détecter d’autres cas éventuels de fraude, ou encore d’identifier des tiers qui peuvent éventuellement être impliqués, eux aussi, dans une fraude systémique ou dans d’autres activités illégales. Nous travaillons pour l’instant sur un modèle de nouvelle génération qui facilitera ce processus.
Nous étudions aussi la manière de combiner les contrôles de l’évaluation avec des algorithmes de détection sur images de scanographie, en vue de déterminer si les volumes relatifs des marchandises déclarées se rapprochent de ceux apparaissant à l’image. Nous cherchons pour l’heure des partenaires travaillant dans le domaine des technologies d’inspection non intrusive afin d’entamer une collaboration avec eux sur la prochaine génération de modèles d’apprentissage automatique incorporant l’analyse des images scannées, dans la perspective de pouvoir les comparer aux informations des déclarations sous-jacentes et des connaissements.
Déploiement
Nous sommes conscients du fait que les données douanières sont sensibles et que de nombreux pays ont mis en place des législations strictes en rapport avec la souveraineté des données et le partage de données. Fort heureusement, nous pouvons déployer notre technologie au sein d’un centre de données appartenant à la douane, sur un nuage informatique ou encore dans le cadre d’une solution hybride où tous les modèles portant sur la fausse classification et l’évaluation sont déployés sur place, mais où des petits jeux d’informations anonymisées et codifiées sur les destinataires sont envoyés vers notre Trade Data Network en utilisant une connexion sécurisée et chiffrée vers notre service de nuage privé.
En outre, nous pouvons travailler avec toutes sortes de données douanières et nous pouvons recevoir ces données soit à travers une interface de programmes d’application, soit en accès de lecture direct des tableaux sous-jacents de la base de données. Les données historiques fournies par une administration des douanes en format csv ou tout autre format semblable peuvent également être traitées de manière effective.
N’hésitez pas à nous contacter si vous désirez recevoir davantage d’informations à ce sujet. Nous figurons parmi les exposants à la prochaine Conférence de l’OMD sur la TI en Indonésie. Nous vous invitons donc à passer par notre stand pour discuter de vos besoins et des solutions que nous pouvons vous proposer.
En savoir +
www.ttekglobal.com