

Aux États-Unis, par exemple, le département du Commerce utilise les Export Control Classification Numbers (ECCN ou numéros de classification pour le contrôle à l’exportation) en guise d’identifiants pour classer les articles qui sont soumis à des exigences de contrôle à l’exportation. Les ECCN couvrent principalement les produits de nature stratégique. Le service de la Douane et de la protection des frontières des États-Unis (CBP) utilise, pour sa part, le Harmonized Tariff Schedule of the United States (HTS/US ou Grille tarifaire harmonisée des États-Unis), basée sur le Système harmonisé (SH) international. Il est difficile d’établir des liens entre les codes ECCN et HTS. Les relations directes entre le HTS et les ECCN sont rares. Un bien stratégique pourrait être expédié sous une kyrielle de codes HTS et un même code HTS peut couvrir plusieurs ECCN. De plus, de nombreux articles soumis à contrôle comprennent des équipements ou matériels industriels et scientifiques ayant des spécifications techniques bien précises ; or, les désignations des codes SH ne se réfèrent pratiquement jamais à ce type de spécifications.
L’ensemble de ces facteurs complique grandement la tâche des autorités qui essaient de détecter les éventuels mouvements illicites de produits stratégiques. Le contrôle des transactions fondé sur des tables de concordance statiques inexactes entre les codes du SH et ceux utilisés dans les listes de contrôle, ou encore sur la base des informations concernant les parties impliquées dans les transactions concernées, ne suffit tout simplement pas pour servir les objectifs d’un système de contrôle des échanges de nature stratégique qui se voudrait efficace.
La méthodologie proposée dans le présent article invite à tirer parti des grandes quantités de données relatives à une transaction qui sont recueillies par les gouvernements en exploitant les possibilités qu’offre l’apprentissage automatique, c’est-à-dire le processus d’apprentissage d’un système informatique qui lui permet de formuler des prévisions précises lorsqu’il est alimenté en données.
Apprentissage automatique et commerce international
Une méthode mise au point afin de résoudre un problème assez courant de l’apprentissage automatique se prête bien à l’identification de transactions impliquant des biens stratégiques: la détection des données aberrantes ou atypiques. Cette méthode est utilisée dans des domaines les plus divers, par exemple, pour identifier l’utilisation frauduleuse d’un instrument de paiement, les trafics suspects en matière de cybersécurité, la découverte de maladies et de nombreux autres problèmes où la cible est un comportement hors norme. Etant donné que les échanges stratégiques représentent une petite proportion du commerce dans son ensemble, les transactions impliquant des articles soumis à des contrôles peuvent être considérées comme atypiques. Ces transactions sont non seulement peu courantes mais elles sont aussi susceptibles de sortir du lot compte tenu du fait que les marchandises échangées sont habituellement des matériaux et des équipements techniquement sophistiqués. Ces spécificités peuvent se traduire en soi par des valeurs unitaires plus élevées, par de plus faibles quantités échangées, par des partenaires commerciaux spécifiques ou par d’autres caractéristiques qui distinguent les transactions couvrant des articles stratégiques des autres.
Les paragraphes qui suivent visent à présenter une approche de base pour l’utilisation de l’apprentissage automatique dans le but de repérer les transactions impliquant des biens stratégiques qui n’ont pas été déclarés en tant que tels. Cette démarche se fonde sur les données commerciales historiques concernant les transactions de produits avec et sans ECCN. Les modèles créés en conséquence sont ensuite appliqués aux nouvelles transactions afin d’estimer la probabilité qu’elles soient liées à un produit stratégique donné. Il s’agit d’une approche d’apprentissage supervisé ; le but est « de former » les modèles afin qu’ils « apprennent » en fonction des données historiques dont les résultats sont déjà connus – l’envoi porte un ECCN et contient un article de nature stratégique ou ne porte pas d’ECCN et ne contient pas de produit stratégique – pour les appliquer ensuite aux nouveaux cas se présentant. Un bref récapitulatif de la méthodologie est présenté ci-après. Pour plus de facilité, les codes du HTS/US sont appelés ici codes SH.
Méthodologie
La démarche proposée permet de créer un modèle d’apprentissage automatique pour un produit de nature stratégique spécifique, sur la base de son ECCN. Le processus peut être répété pour créer un portefeuille de modèles pouvant être utilisés pour classer les transactions impliquant plusieurs articles stratégiques différents. La première étape dans ce processus consistera à choisir un produit stratégique pour la modélisation, en fonction de son ECCN.
Une fois que l’ECCN a été choisi, il s’agira d’extraire et de regrouper les données concernant les transactions reprenant cet ECCN dans les documents d’expédition sur une période de temps donnée. Plusieurs facteurs très variés peuvent être choisis pour élaborer ce modèle, notamment, le code SH, les exportateurs/destinataires, la destination, le poids, la quantité, la valeur, etc. Une fois que ces données sont recueillies, un « panier » des différentes combinaisons des codes ECCN et SH pourra être créé. Ce panier montrera la fréquence à laquelle un code du SH particulier est utilisé par les exportateurs pour des transactions impliquant l’ECCN choisi (par exemple, 45 % des transactions portant sur des biens stratégiques classés sous l’ECCN « X » est expédié en utilisant le code SH « Y »). Cette technique permet de déterminer quels sont les codes du SH qui sont activement utilisés par les exportateurs pour les transactions portant sur le produit stratégique étudié, contrairement à la table de concordance qui détermine le code du SH qui devrait être utilisé pour ce même article.
Les paniers SH-ECCN contiendront souvent des codes SH qui sont très peu utilisés pour une transaction. Afin d’éviter d’inclure trop de cas « rares » lors de l’étape suivante, un seuil de pourcentage de corrélation devra être défini.
Une fois que les codes SH correspondant à un haut niveau de corrélation auront été relevés, il s’agira de collecter les données relatives aux transactions portant ces codes SH mais sans ECCN, pour la même période de temps pour laquelle les transactions portant des ECCN ont été recueillies. Tous ces éléments vont former l’univers à partir duquel il sera possible de modéliser les caractéristiques des échanges du produit stratégique à l’étude.
Le nombre de transactions impliquant des biens stratégiques est bien inférieur à celui des échanges non stratégiques. En d’autres mots, il se dégage une classe majoritaire (transactions ne portant pas d’ECCN) et une classe minoritaire (transactions portant un ECCN). En apprentissage automatique, les données hautement déséquilibrées peuvent avoir des effets indésirables sur la modélisation et sur les mesures traditionnelles de la performance. Afin d’ajuster les modèles en conséquence, les données transactionnelles doivent être ré-échantillonnées pour rééquilibrer la classe minoritaire par rapport à la classe majoritaire. À cet effet, la méthodologie proposée utilise la technique du sur-échantillonnage des minorités (SMOTE) qui répertorie les exemples similaires dans la classe minoritaire et crée de nouvelles instances en combinant les caractéristiques d’un cas existant avec celles de ses voisins. Plutôt que de simplement dupliquer les transactions, cette technique offre de nouveaux exemples artificiels de la classe minoritaire.
Une fois préparées, les données sont prêtes à être utilisées pour créer un modèle. À ce stade, la forêt d’arbres décisionnels est utilisée pour prédire si une transaction implique un bien stratégique ou pas. Cet algorithme crée plusieurs arbres de décision en fonction de caractéristiques choisies au hasard et d’échantillons de données, en vue de déterminer si une transaction peut être classée comme impliquant un produit de nature stratégique ou pas. Les résultats de chaque arbre de décision sont ensuite regroupés et, puisque nous sommes face à une classification binaire, la classification finale sera celle choisie par la majorité des arbres de décision. Le graphique n° 1 est une représentation simplifiée de l’algorithme de la forêt d’arbres de décision (ou forêt aléatoire).
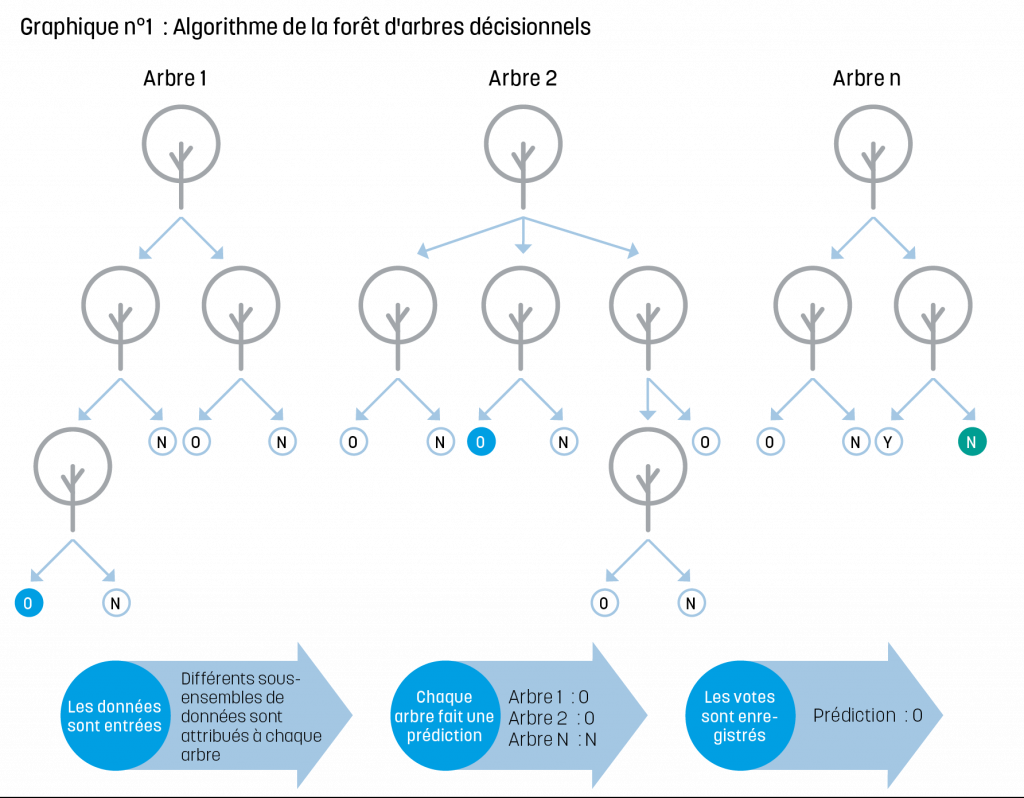
L’algorithme « apprendra » sur la base d’un sous-ensemble de données et sa performance sera mesurée à l’aune d’un autre sous-ensemble réservé à la mise à l’essai. En fonction des résultats, les paramètres ou les caractéristiques pourront être modifiés afin d’accroître le rendement. Une fois que la démarche aura été essayée pour un article stratégique donné, lié à un ECCN spécifique, elle pourra être utilisée de manière répétée pour créer des modèles couvrant un vaste portefeuille de biens stratégiques et appliquée au fur et à mesure que de nouvelles données arriveront.
Avantages et applications éventuelles
Alors que le nombre de transactions ne cesse d’augmenter chaque jour, les modèles créés pour classer les produits stratégiques pourront être améliorés, ajustés et retravaillés en suivant le même concept méthodologique. De plus, puisque cette approche propose d’utiliser des données exigées par l’État, les modèles seront intrinsèquement conçus pour identifier les marchandises stratégiques dans le contexte de ce même État, et devront prendre en compte sa géographie, ses partenaires commerciaux et ses capacités industrielles. Enfin, l’informatique distribuée et les services de nuage informatique, en plein essor actuellement, permettront aux autorités gouvernementales d’analyser et de créer des modèles pour un volume beaucoup plus vaste de données que ce qui pouvait être traité il y a à peine cinq à dix ans.
La méthodologie décrite dans le présent article peut être appliquée à un large éventail de domaines. Du point de vue de la lutte contre la fraude, cette approche permettrait de mieux cibler les transactions, en utilisant des données du monde réel, et d’optimiser les vérifications et les contrôles d’utilisation finale. Par ailleurs, la modélisation basée sur un jeu choisi de produits stratégiques hautement prioritaires pourrait permettre aux douanes d’améliorer l’affectation de leurs ressources et de mieux motiver les contrôles qu’elles auraient à mener. Cette démarche permettrait aussi aux États de mieux comprendre les flux commerciaux les plus courants de produits stratégiques et d’établir les points de destination finale ou les points de transbordements les plus habituels pour ces marchandises.
En outre, la méthodologie pourrait venir renforcer les programmes de mise en conformité et être utilisée pour concevoir des initiatives de communication auprès des opérateurs économiques concernés. En effet, dans de nombreux pays, l’un des grands défis liés à l’application de contrôles à l’exportation est la sensibilisation et l’information des parties prenantes. Le secteur privé a besoin d’assistance afin de pouvoir identifier, gérer et atténuer les risques associés aux contrôles de marchandises à double usage et de garantir le respect des règlementations. Grâce à des modèles « formés » en fonction des données existantes, il serait possible de repérer les transactions qui correspondent au profil d’un bien stratégique mais pour lesquelles l’importateur ou l’exportateur n’a pas demandé la licence requise. La douane pourrait alors contacter les entités impliquées dans les transactions en cause afin d’entamer un dialogue et de proposer une formation sur les règlementations de contrôle à l’exportation. Elle pourrait également faire un inventaire des flux commerciaux habituels pour les transactions sans licence qui correspondent aux profils des biens stratégiques et lancer des initiatives de sensibilisation et de formation à l’échelon international.
Puisque la méthodologie se fonde sur un panier de codes du SH, elle pourrait aussi être utilisée pour compléter les tables de concordance existantes entre le SH et les ECCN et améliorer ces concordances dans l’ensemble du système. Tout d’abord, les paniers SH-ECCN donnent davantage de « poids » aux concordances, grâce aux transactions historiques impliquant des biens stratégiques. Ils permettent de déterminer quels sont les codes SH qui sont utilisés dans la pratique et à quelle fréquence, ajoutant ainsi une couche de détails supplémentaires aux tables de concordance statiques, et de corréler un ou plusieurs éléments à plusieurs autres. Ensuite, l’analyse des paniers SH-ECCN devrait permettre de relever les corrélations et les faux classements les plus courants des produits stratégiques. Ces informations pourraient être utilisées pour les efforts de sensibilisation ou encore pour proposer des amendements futurs au SH, le but étant de rapprocher davantage les codes SH et ECCN.
Au fur et à mesure que le volume de données recueillies augmentera et que les initiatives de sensibilisation et de lutte contre la fraude s’affineront, les modèles d’apprentissage automatique devraient devenir plus performants, créant ainsi un cycle d’amélioration continue. Les systèmes de contrôle des échanges de nature stratégique pourraient être grandement améliorés en exploitant les grandes quantités de données déjà collectées par les gouvernements et en tirant parti des modèles d’apprentissage automatique. Utiliser ces modèles dans un objectif alliant répression et sensibilisation devrait permettre d’améliorer les capacités de détection de la fraude et de promouvoir un système de commerce international plus sûr.
En savoir +
chris.nelson28@gmail.com
Pour des informations plus détaillées sur la méthodologie utilisée, voir l’article de l’auteur publié dans le World Customs Journal (Volume 14, numéro 2, septembre 2020).